Is NLQ the Future of Analytics?
6 min read | Published


We have seen significant progress in natural language processing (NLP) in recent years. From the latest achievements, it is worth mentioning No Language Left Behind (NLLB) – a universal open-source translator from Meta, DALL-E – a popular machine learning model from OpenAI which generates a realistic picture from a natural language description, Stable Diffusion – an open-source alternative to DALL-E, and many other machine learning models.

Now imagine that we could see a similar boom in analytics. We could predict what insights we want to derive from our data, and we would see them nicely visualized. I want to dedicate the remainder of this article to this proposition.
I will discuss natural language querying (NLQ), its application in analytics, existing solutions, and their pros and cons. After all this, I would like to propose a simple NLQ approach in analytics and discuss the future of (not only) NLQ in analytics.
What Does NLQ Bring to Analytics?
We can define natural language querying as converting natural language description into a query (e.g., SQL). NLQ can simplify analytics – by using natural language description instead of an SQL statement. It might sound like the target audience is business users unfamiliar with SQL, but that does not have to be necessarily true. Natural language is a universal language we have all been learning since childhood, and we can all benefit from being able to use it.
Thanks to NLQ, we can bring analytics to more users and make it more user-friendly. Most companies use MS Teams, Slack, etc., for communication. As a user who wants to share a data visualization or a dashboard, I need to go to the analytics application, export or screenshot the visualization or dashboard and then send it to my colleagues. With the help of NLQ, we're paving the way for tools like messaging bots that will let you create or access data visualizations using messaging tools.
The last benefit I would like to mention is maintainability. Using natural language could bring self-documentation – storing natural language query as semantic property to a requested object. The typical approach is to separate documentation into other semantic properties (e.g., title, description). It could help with faster onboarding of people who see the data visualization for the first time – they would see what queries/questions are answered with it.
Thinking of NLQ as a generator of SQL from natural language descriptions in modern analytics tools seems wrong. The reason is that modern analytics tools do not execute SQL queries directly but instead use a semantic layer with their representations (languages) instead. Therefore, we would like to utilize the semantic layer and build natural language querying on top of it. The main benefit of this approach is that building NLQ on top of the semantic layer should be more straightforward than building NLQ directly on top of a database.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product toursHow Is NLQ Used Today?
At the time of writing this article, when I searched for "analytics nlq", the most relevant results were implementations from Sisense and Yellowfinbi. Of course, we can also find implementations backed by big companies such as Power BI and Tableau as well.
These utilizations are closed approaches (closed source) – we cannot, or we can only partly modify, change, or customize the logic behind NLQ, and we do not see what is happening under the hood. The critical thing to note is that BI tools providing NLQ support put themselves as “experts” on NLQ. I believe BI tools should focus primarily on analytics and leave the NLQ to someone who understands it better. As a result, these approaches become counterproductive.
Let us have a look at how the drawbacks above could be handled. GoodData is based on headless BI analytical architecture, which decouples the analytical backend from the presentation layer – it exposes the semantic layer using REST APIs, JDBC, SDKs, etc. Headless BI gives us the power to reuse analytics in other applications or tools (for example ML/AI platforms, BI tools, notebooks) and yet it lets us keep heavy computation on the analytics backend. I explored the power of headless BI many times, and if you are keen to learn more, look at my other articles (How To Automate Your Statistical Data Analysis, How To Maintain ML-Analytics Cycle With Headless BI?). In the following chapter, I want to explore an implementation of NLQ on top of GoodData.
Build a Simple NLQ on the Top of the Semantic Layer
Disclaimer:
The goal of this chapter is not to propose/implement the NLQ solution itself, rather it is to introduce a trivial integration of the semantic layer with the NLQ solution. I will not comment on the implementation of NLQ on the top of the semantic layer itself in this article. I would like to write a follow-up article that will be purely dedicated to this implementation.
Let me first define the goal we want to reach. We want to build a simple NLQ on top of our running instance of GoodData with defined metrics, visualizations, and dashboards. For the sake of simplicity, let us work only with existing metrics.
Thanks to the semantic layer, we find ourselves in a JOIN-free world. We do not need knowledge about tables, the analytics engine takes care of that for us. We cannot forget the power of metrics that are available to us. Metrics define only aggregation without context (an alternative name for context is dimensionality). Thanks to metrics, we also find ourselves in a GROUP BY-free world.
We saw that utilization of the semantic layer enormously simplifies our work. We need to propose the implementation of NLQ. Let's offer something similar to Yellowfinbi's solution. The goal is not to present the best NLQ for analytics but to show the benefits of the semantic layer.
An essential part of NLQ implementation is listing attributes, facts, and metrics. Thanks to the semantic layer, we can access attributes and facts in the semantic model and metrics in the analytics model. NLQ aims to show data visualization to the user. We can think of data visualization as a combination of attributes, facts, and metrics. Let us expect that our natural language query engine returns such a combination, and we want to validate if such a combination is valid or not, or if the user can add more things to the data visualization. We can use GoodData's validObjects as a primitive implementation of suggesting semantically correct entities in the current context. I am convinced that such a feature is essential for implementing NLQ on the top of the semantic layer.
Let us look at the difference between implementing NLQ on top of the semantic layer and implementing it on top of SQL.
We have the following natural language query:
What is the revenue where the customer region is west?
Note: The revenue is quantity multiplied by the unit price of sold items.
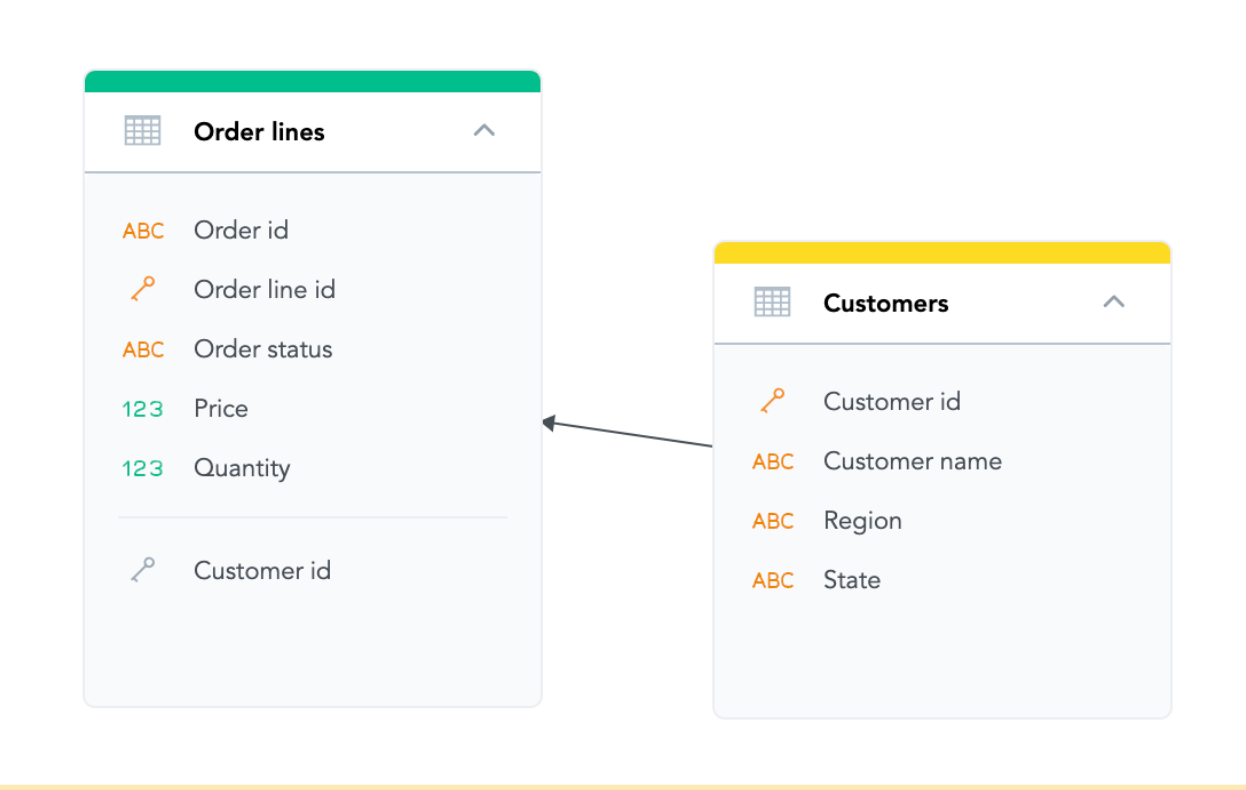
We can see the tables we will be querying above, represented as datasets. As you can see, the solution using SQL will not be trivial, and we will need to use the JOIN clause, aggregation, and filtering. The SQL getting desired result is the following:
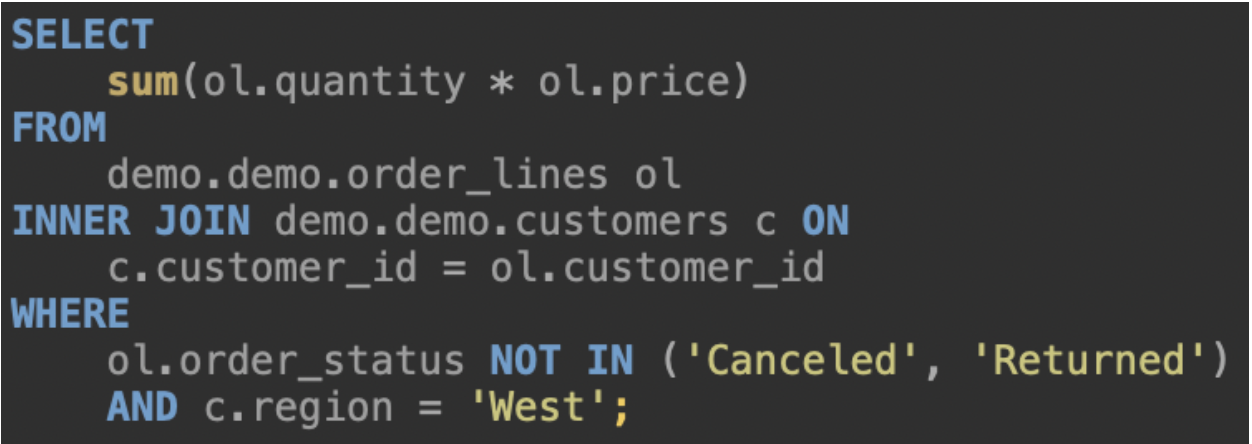
The approach will become much more manageable when we want to solve the same natural language query using a semantic layer. We already have a revenue metric, which we can easily reuse in our solution.

Then all we need to do is to fill in what columns we want to query and what we want to filter.

The following images show a simple implementation of NLQ on the top of the semantic layer using the approach above.
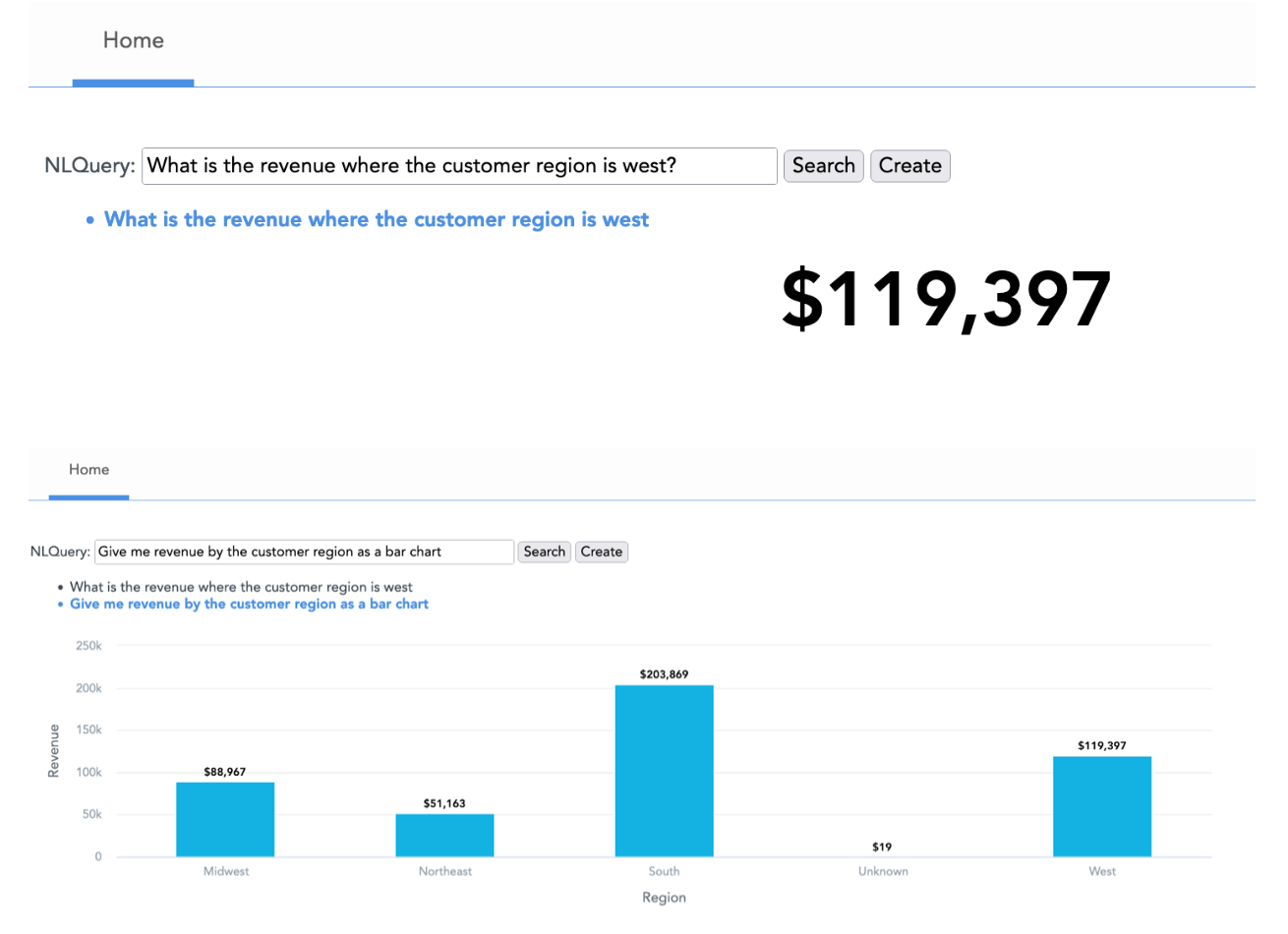
While building NLQ on the top of the semantic layer, I noticed several things I would like to mention. I think that users will appreciate free-form descriptions more than stricter ones when forming a natural language query.
Another benefit of free-form descriptions is maintainability. Using natural language could bring a sort of self-documentation. The current typical approach is to separate documentation into other semantic properties (title, description). It could help with faster onboarding to people who see the insight for the first time – they would see what queries/questions are answered with it. Self-documentation could also be utilized in semantic search, for example for model refinement.
There Is Even More
Let us look beyond what we have been talking about up to now. Thanks to technologies that primarily focus on interaction with humans (e.g., virtual assistants, virtual reality (VR), augmented reality (AR), and mixed reality (MR)), we are exploring new areas of NLQ usage. The utility of NLQ is incalculable, and I believe there will be a lot more applications of NLQ put into practice in the near future.
Thanks to the semantic layer, we can improve the accuracy of the NLQ far more than without it. The semantic model contains far more information than the physical data model, and we have information about datasets relations, type (attribute, fact, date), and documentation (title, description). All described features will help NLQ to understand the context better.
Conclusion
We showed that the implementation of NLQ on the top of the semantic layer can be straightforward, mainly thanks to its JOIN-free and GROUP BY-free nature of it. Unfortunately, the semantic layer is not standardized in BI tools, so NLQ implementations are not portable. I think that the standardization of the semantic layer would help us not only in the context of NLQ solutions but it could help address other challenges the BI community faces and help us implement lasting solutions. Lastly, the standardized semantic layer could allow data sources to be adapted and optimized for a more performant rate of data exchange.
This article started as a question related to using NLQ in analytics but ended up emphasizing the importance of a standardized semantic layer. Let me give you a proper answer to the question posed in the title of this article. Is NLQ the future of analytics? The presence of NLQ in analytics is undeniable, but to transform it into a mainstream solution, we need to first make it straightforward, transparent, and portable. This is something we may be able to achieve if we as a community focus on implementing a standardized semantic layer.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product tours



