Is MotherDuck ProDUCKtion-Ready?
11 min read | Published


You have seen many announcements regarding integrations with DuckDB/MotherDuck in the past months. I am quite conservative, so I am not the first to jump on the hype train. I want to be sure about new technology before publicly announcing a new integration.
Thanks to my conservatism, I made time to properly evaluate MotherDuck. Now I can thoroughly inform you whether or not MotherDuck is producktion-ready (so we can use it in GoodData and recommend it to our customers).
Moreover, my article shows you all the important differences between DuckDB/MotherDuck and other databases, including results from the first iteration of performance tests.
Let’s start!
What the Heck Is DuckDB/MotherDuck?
If you haven’t heard about DuckDB/MotherDuck yet, let me quickly onboard you. MotherDuck data source is DuckDB-as-a-service, plus a few exciting features.
DuckDB is an in-process OLAP database that is:
- Very easy to use in all major programming languages and can even run in web browsers through WebAssembly (WASM)
- Very, very fast (columnar, vectorized execution engine, etc...)
- Feature-rich (SQL, integrations, etc..) and straight-up invents features we have been missing for decades, such as GROUP BY ALL
- Open-source, easily extensible
MotherDuck, standing on DuckDB’s shoulders, provides:
- Serverless deployment in a cloud
- Users can connect using standard protocols - JDBC, ODBC, …
- SQL executions are automatically optimized; Imagine running SQL on top CSVs stored across multiple regions
- Optimized storage for data and caches
- Interesting new concept - hybrid execution, which can combine source data stored on both the client’s and server’s side
Onboarding as Usual
Nothing new here. I always look for documentation and community.
Generally, MotherDuck excels here! Many of my questions in the community were answered by their CEO 🙂
Integrating Semantic Layer With a New DB Engine
This is the way GoodData follows.
Our customers appreciate the semantic layer because it:
- Decouples end users from the physical representation of the data
- Provides a higher metric language on top of SQL
- Is easier to define metrics (in our case we use the MAQL language)
- Is easier to migrate between DB engines
To support a new DB engine, we have to be sure that all metric concepts, once translated to a particular SQL dialect of the DB engine, can be executed and return correct results. Generally, it is a perfect test of the capabilities of DB engines. This is why I am confident that the DB engine is producktion-ready, when all the tests are passing. Now, let me take you through my path when integrating MotherDuck.
Building Minimum Viable Produckt(MVP)
Context:
GoodData provides a custom analytical language called MAQL, powered by a Logical Data Model(LDM). You should read this short article by my colleague Jan Kadlec, which briefly describes the basics.
When we want to integrate a new database engine, we have to be able to translate any MAQL metric to the SQL dialect of this new engine.
However, MVP is quite simple:
- Add a new JDBC driver
- Register a new DB type in relevant APIs and gRPC interfaces
- Inherit behavior from PostgreSQL ( Metadata scanning, SQL Dialect, SQL queries execution)
However, I ran into the two following issues:
The first issue is that the jdbc:duckdb:md:<db_name> cannot be parsed as a valid URL. To solve this, I turned it off, and later, I created a custom parser. We parse it for user convenience.
The second issue I encountered was with MotherDuck drivers allowing users to access the local filesystem. It is OK if you run the client on your laptop, but if we connect from our SaaS infra, we have to disable it!
And the solution is quite simple! Simply set saas_mode to true.
Funny insert - reading /etc/passwd
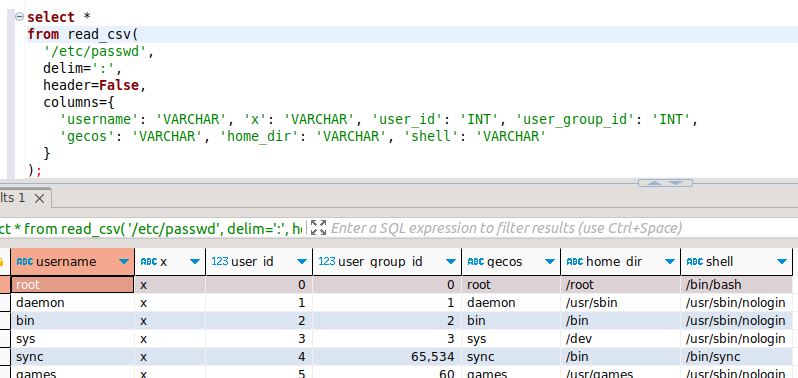
Then I tested the MVP:
- Registered to MotherDuck (SIGN UP button on the home page)
- Created an auth token (https://app.motherduck.com/ -> User settings -> Service token)
- Registered a new data source in GoodData pointing to MotherDuck
- Scanned and created a logical data model
- Created a metric, report(insight), dashboard, execute them
Did it work out of the box?
MotherDuck suffers from not being fully compatible (SQL dialect) with the PostgreSQL database family(e.g., Redshift, Vertica). But basic reports worked with no issues.
The typical issue you hit: at least some operations with dates/timestamps don’t work. That happened here too. Will there ever be one standard for working with dates in SQL? I know it's more science fiction, but I still hope. 🙏
Beta
How do we prove that a DB engine is beta-ready?
DuckDB executes over 2000 SQL tests to validate any changes. Impressive!
We have developed over 700 tests during the last 15 years, laser-focused on analytics use cases that users can meet in GoodData. In general, they can meet them in all BI platforms whether they provide a higher language such as our MAQL or just raw SQL interfaces).
We validate that SQL queries can be successfully executed against the database and that their results are correct (except floats - we tolerate differences up to a configurable delta).
Use cases worth mentioning:
- Aggregation functions - SUM, COUNT, MEDIAN, …
- Logical operators - AND, OR, …
- Mathematical functions - SQRT, LN, …
- Running total functions - RUNSUM, RUNSTDEV, …
- Ranking functions - OVER PARTITION BY in SQL, including FRAMING
- Conditional statements - CASE, IF THEN, …
- Datetime arithmetic and transformations, including infamous TIMEZONEs
To illustrate the complexity: the most complex test generates a circa 20-page-long SQL query containing a mix of various edge cases. Although it queries small tables, it does not finish under 10 seconds on any supported database!
So, what obstacles did I meet before all the tests passed?
Loading Test Data
Before running the tests, we must be able to load test datasets into the new database engine. We have developed seven models, each focused on a subset of use cases. Some are synthetic (TPC-H), and some are quite realistic projects, e.g., our internal Sales project.
In the case of MotherDuck, I used Python duckdb-engine (SQLAlchemy). Later, when I upgraded to 0.9.2, dependency on duckdb library was not defined anymore, so I had to upgrade it explicitly (and add it to requirements.txt).
Then, I set the MOTHERDUCK_TOKEN env variable and finally could connect to MotherDuck:
self.engine = create_engine(
f"duckdb:///md:{self._database_name}"
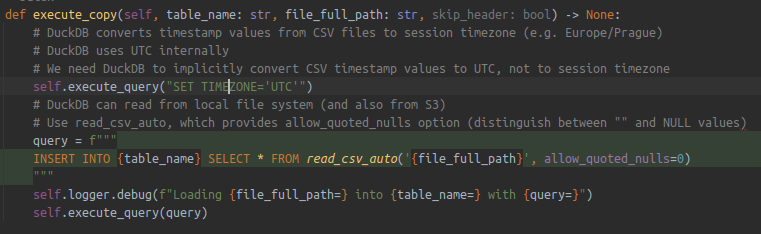
)However, I ran into some issues:
- TIMESTAMP WITH TIMEZONE values (in other than UTC zone) are not loaded correctly.
Solution: execute a SET statement (see the source code below). - FLOAT data type behaves differently. Loaded values are slightly different.
Solution: I changed FLOAT data type to DOUBLE (configurable in our tooling). - Empty string values are loaded as NULL.
There is a simple solution. Just use the allow_quoted_nulls property (see the source code below).
Executing tests
I executed the tests on top of the result of the MVP described above (PostgreSQL dialect generated), and hundreds of tests failed, as usual. ;-)
Then I spent circa three days fixing them while heavily communicating with the MotherDuck community. Fun!
Let me recap the most interesting use cases I had to implement, from simple to complex.
Table Sampling
The syntax is different from what we have seen in other databases so far.
Snowflake:FROM <table> TABLESAMPLE(10)
DuckDB: FROM <table> USING SAMPLE 10
Moreover, DuckDB does not support decimal percentage values, so I truncate the value before generating SQL. Once this feature becomes important for our end users, I will file an issue to DuckDB Github.
Generate Series
God bless DuckDB for providing the GENERATE_SERIES function. It is so important! Some databases do not provide it. ☹️
It is especially important for generating timestamp series - we outer-join them with data to fill in missing values.
DuckDB needs to add an UNNEST function in addition to what, for example, PostgreSQL requires.

Why is UNNEST needed here?
Alex from MotherDuck: “The reason is that DuckDB's generate series can be used in a from clause as a table function or in a select clause as a scalar function that produces a list. Unnest converts the list into separate rows!”
Truncate Numbers
TRUNC() is the opposite function to CEIL(), always rounding down.
Interestingly, only some DB engines accept two arguments, truncating the last decimal point always down. Example: TRUNC(1.29, 1) = 1.2
DuckDB does not support it either.
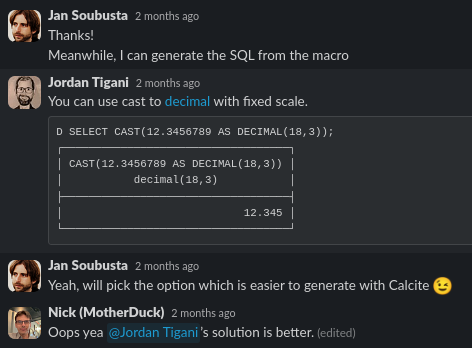
MotherDuck CEO Jordan Tigani proposed a nice workaround: CAST(1.29 AS DECIMAL(18, 1)) = 1.2
Unfortunately, it does not always work. Example: TRUNC(1.29, TRUNC(1.1))
Don’t ask me why we accept decimal values from end users in this case ;-)
Anyway, CAST(1.29 AS DECIMAL(18, TRUNC(1.1)) is not a valid statement.
Date Arithmetic

Date arithmetic in SQL is an absolute nightmare for all data engineers. The syntax is very different in each database family and some date granularities are defined using highly complex algorithms. The worst-case scenario is ISO weeks. This is a screenshot from the corresponding Wiki page:

It looks like something from a quantum mechanics book, doesn't it?
We already had to implement the arithmetic for many databases (PostgreSQL, Snowflake, BigQuery, MSSQL, etc.), so we grok it. To not make it too easy for us, we provide non-standard use cases to our customers, such as comparing the current ISO week with the same week in the previous year. Really funny to calculate something like this!
Furthermore, we must respect US/EU weeks starting on Sunday/Monday. 🙂
So, what did we have to implement in the case of DuckDB?
Date formatting is different from PostgreSQL, but we are ready to override it easily:

There is no TO_CHAR function in DuckDB. Instead, we generate STFTIME or STRPTIME function depending on whether the first argument is literal (e.g. ‘2023-01-01’) or an expression (e.g. column_name).
Weeks and quarters are complicated. We generate something like this:
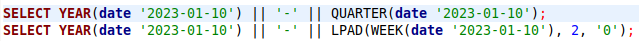
But unfortunately, it is not enough.
I always mentioned the use case when we need to shift a date from an ISO week to a day in the same ISO week in the previous year.
Example: 2023-01-01 -> 2022-52 -> 2021-52 -> 2021-12-27(Monday)
We need to extract the TIMESTAMP data type in the end because we may use it, for example, as a filter in an outer query. There is no way to convert the YEAR-WEEK to TIMESTAMP data type in DuckDB. The same is valid for quarters. I am discussing it with the community.
Producktion
OK, so almost all functional tests are passing now. Are we ready to release the integration to producktion? Unfortunately, not yet. Besides the issues already described above (ISO weeks, TRUNC), I found two more.
Serializing Quantiles with Decimals
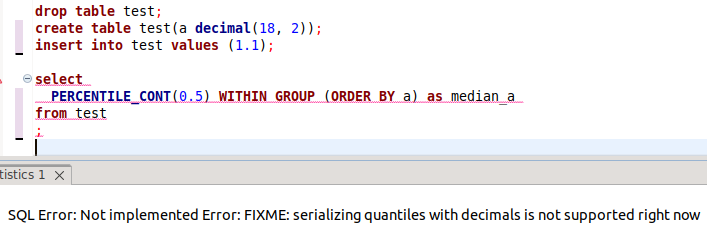
I reminded the community, and the response amused me:
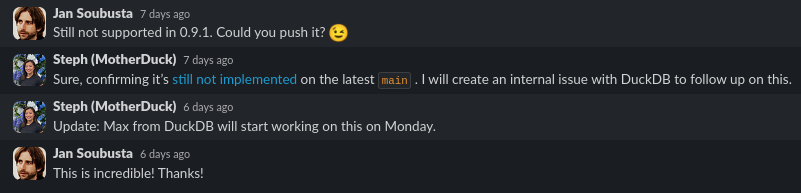
UPDATE 4.12.2023 - a solution was shipped to 0.9.2. I upgraded the JDBC driver, enabled the related tests, and voila - it works like a charm! Great job, community!
Cancelling (Long-Running) Queries
I asked the community, and Nick from MotherDuck responded that explicit client-side cancels via SQL are not yet supported. Later, he mentioned that DuckDBPreparedStatement.cancel() should do the job. He also described a race condition, which should not affect us.
We realize the cancellation process by opening a separate DB connection and calling a cancel SQL statement there. It is the safest solution in most databases. For example, you can lose the network connection to the DB server and cannot call cancel() using this connection anymore. Sooner or later, we try to implement the proposed solution in our stack and will see how reliable it is.
Why is this use case so important for us?
We provide a self-service analytics experience to end users. Users can create crazy reports, e.g. aggregating huge datasets by primary key. We need to cancel queries running longer than a configurable threshold so as not to overload the database.
Driver Extensions Downloaded in Runtime
Everything above is not blocking us from the release. We can document it as known limitations.
But there is one blocker, unfortunately, and it relates to the behavior of client drivers.
Every time a client connects to the server, it downloads extensions to the client side:
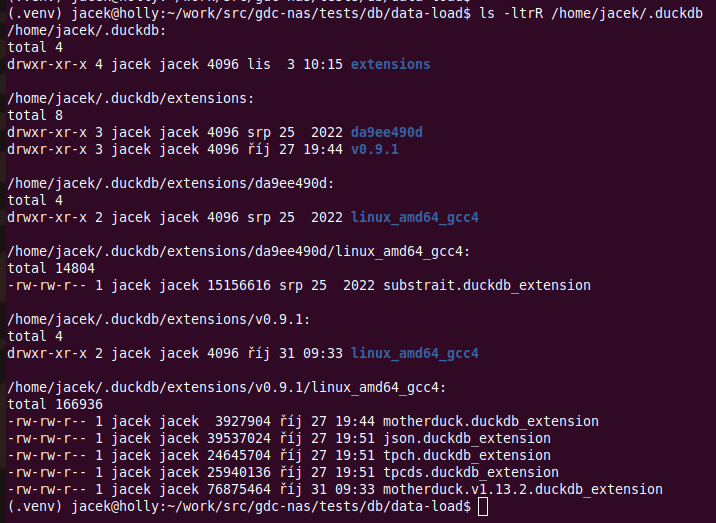
The files are quite big (178M) and must be downloaded the first time you connect, which slows down the connection establishment significantly. But we could live with that.
The real blocker is that the files are downloaded in run-time, bypassing the security scanners we have in our pipelines. This is a no-go for our compliance. ☹️
I discussed it with Jordan in the community. I understand their motivation - they need to innovate the client-server integration rapidly and don’t want to release new clients too often.
As a temporary workaround solution, I am thinking about incorporating the extensions into our docker images. As long as the server accepts the extension version, we are OK. Once they release a breaking change to the server and stop accepting our old extensions, we will release a new docker image with the new extensions. Not production ready, but good enough for our prospects/customers to play with MotherDuck in production (PoC, …).
Looking forward to getting stabilized clients in the future and announcing full pro-ducktion readiness!
Performance Tests
In this iteration, I didn’t want to manage comprehensive performance tests. I plan to do it in the next iteration. Stay tuned!
However, when executing the functional tests, I was curious how MotherDuck performs compared to other supported databases.
I decided to manage the following first iteration of performance tests:
- Compare MotherDuck with Snowflake and PostgreSQL
- Run 700 functional tests with various numbers of threads(DB connections, parallelized execution)
- Run a load of test data (CSV files)
Unfortunately, I hit a bug in our test framework - Kotlin coroutines did not parallelize executions correctly. So, finally, I measured the duration of functional tests while running with only 1 DB connection.
To make a fair comparison:
- All databases are running in
US-EAST-1 - Functional tests are executed from
US-EAST-1 - I implemented a set of Gitlab jobs running on
US-EAST-1workers - I executed a load of CSV files from my laptop (
EU-CENTRAL, lazy to implement relevant Gitlab jobs)
Note: I loaded the results of the performance tests back to MotherDuck and visualized the results in GoodData to evaluate the shortest possible onboarding scenario 🙂

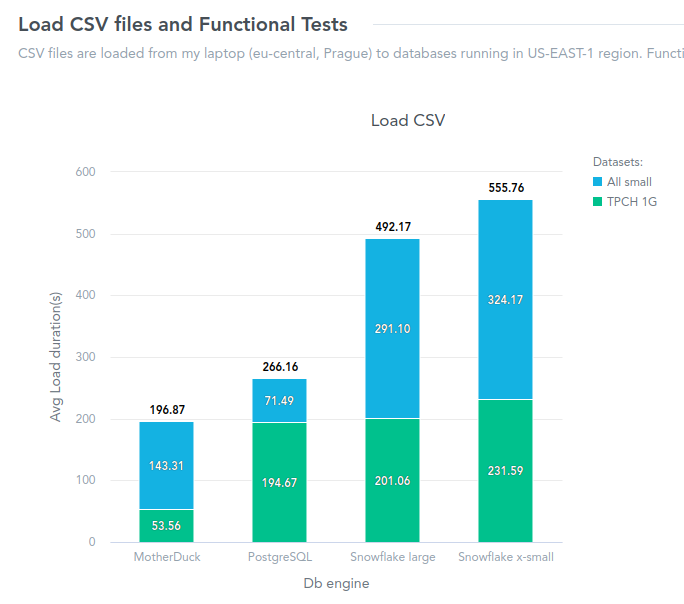
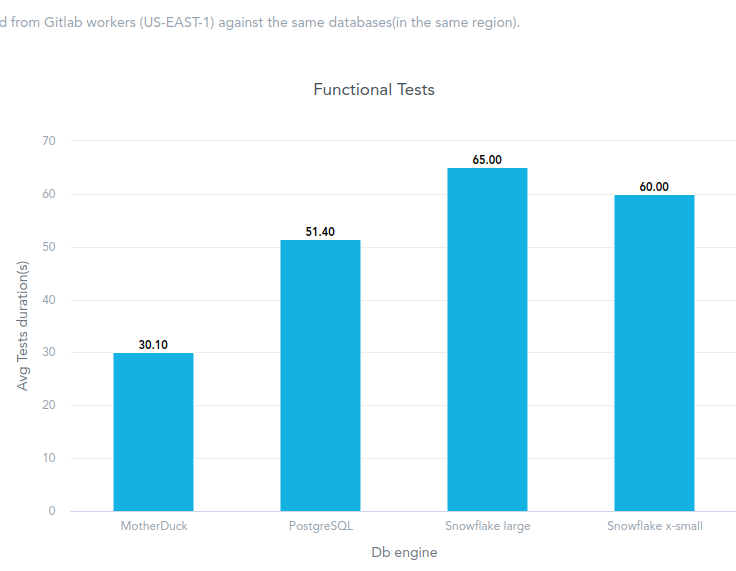
The results clearly show a winner - MotherDuck!
To be fair, I executed tests against two sizes of Snowflake - X-SMALL and LARGE. In this scenario (relatively small data, most of the queries under 1s), a large Snowflake does not bring any benefit. It is even slower in the case of functional tests and only slightly faster in the case of CSV load.
Funny insert:
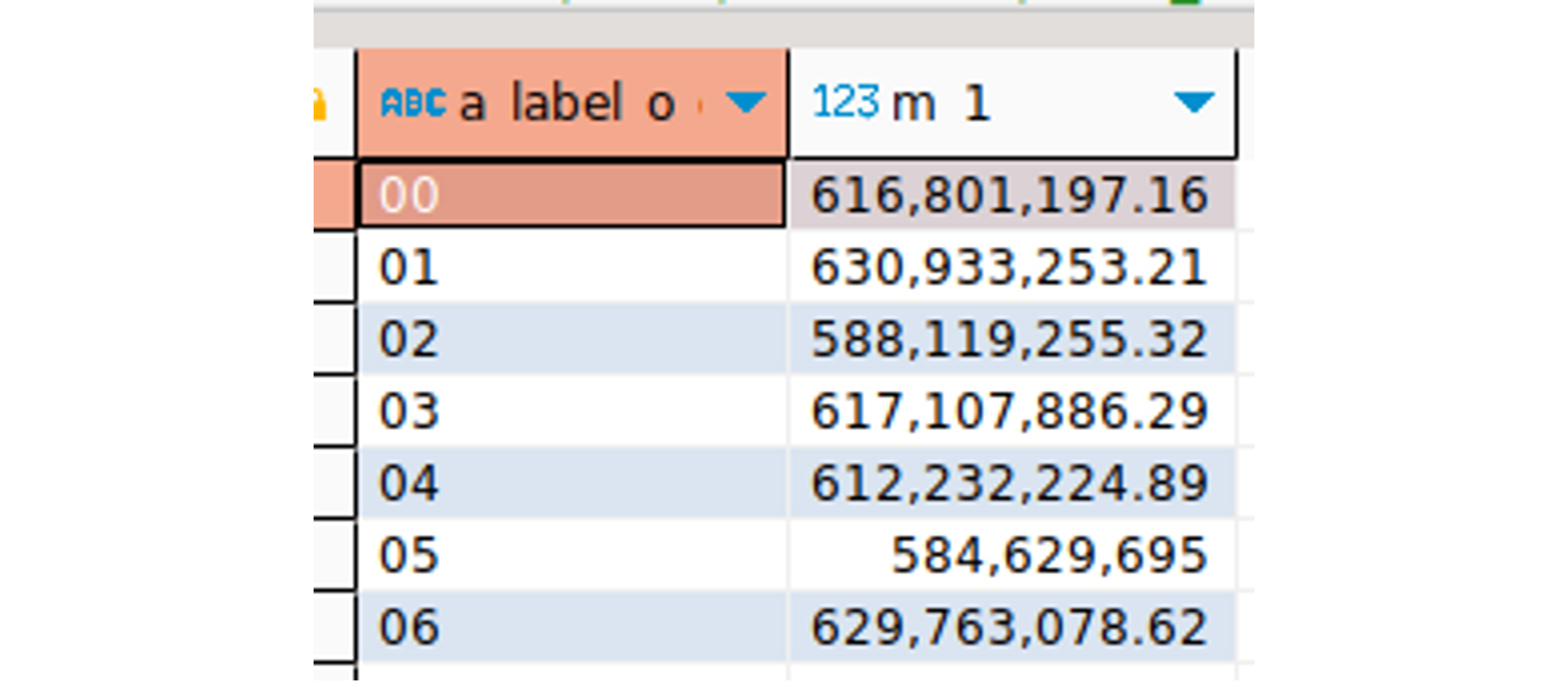
When running functional tests against two sizes of Snowflake, one test returns different results - it calculates different numbers of days in a week. I created a support case for that.
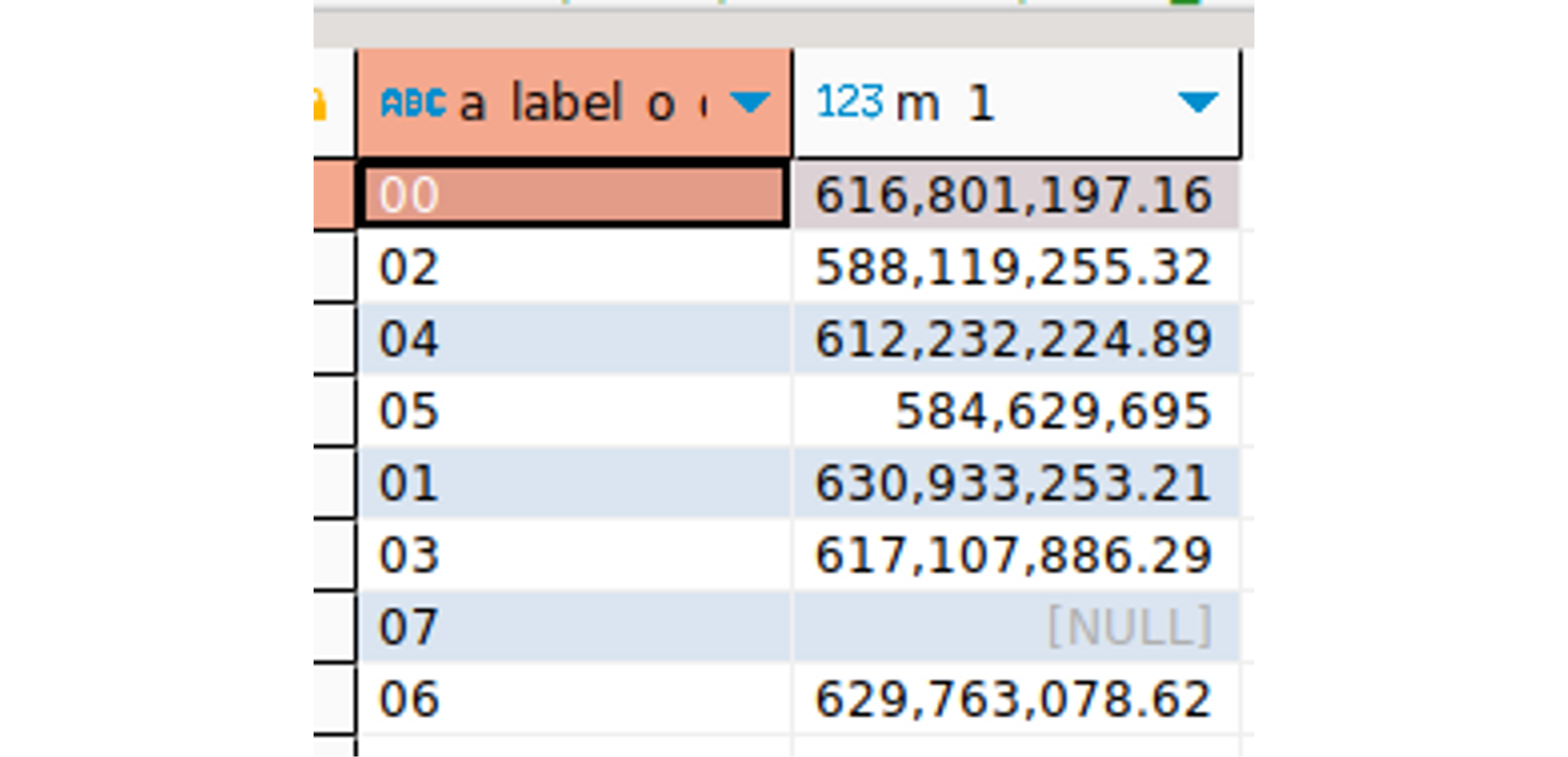
Update: Snowflake support helped us realize we have a bug in our SQL generator! The SEQ4() function can generate different sequences when the warehouse runs in a cluster. We are going to fix this by generating the ROW_NUMBER() function in this case. A common issue in clustered databases.
What Do We as GoodData Expect from MotherDuck?
That is compared to the already supported DB engines.
Saying differently - what should be the key differentiators of MotherDuck?
We expect significantly lower costs (TCO). Not only because it’s a new player trying to penetrate the market but also because of the efficiency of the engine itself. I have already seen a lot of very promising benchmarks where DuckDB outperforms all competitors.
We expect better performance. GoodData is focused on analytics use cases querying small/mid-size data volumes prepared by various ELT processes. DuckDB proved that it is optimized for such use cases. It provides a better latency to more parallel users. That is where all traditional data warehouse vendors struggle. Personally, I have been working with Vertica, Snowflake, BigQuery, Redshift, and others. Vertica provided the lowest latency / highest concurrency, but still, with hundreds+ concurrent users, the (clustered) engine eventually stopped scaling.
Finally, dream with me: the DuckDB(and any other similarly progressive) SQL dialect will become a new defacto SQL standard. DuckDB has already introduced very handy and long-missing features such as GROUP BY ALL or SELECT * EXCLUDE(
What’s Next?
Although the issue related to the extensions downloaded in runtime is a blocker for us, I consider MotherDuck pro-duck-tion ready for analytics use cases.
I want to explore MotherDuck's capabilities in the area of ELT. I already tested the integration with Meltano and dbt, and thanks to help from their communities, I was able to run my complex ELT project successfully. I will write an article about it.
Second, I want to run real perf tests on top of larger datasets. Many people already tested it, but I want to focus on realistic analytics use cases - we execute dashboards, which means executing all reports(insights) in parallel and measuring the overall duration to load each dashboard. Moreover, we spin up tens or even hundreds of virtual users executing these dashboards. Low latency/high concurrency are what matters in the case of analytics(BI).
Last, I want to focus on costs(TCO). I would like to execute heavy tests and calculate TCO for MotherDuck compared to alternative vendors. MotherDuck already published their idea for pricing here. It is very simple, and it seems very promising. Suppose the TCO of MotherDuck is significantly lower, and at the same time, the performance is significantly better. In that case, we can’t do anything else than recommend MotherDuck to our prospects as the default DB engine for analytics. 🙂
By the way, GoodData plays a significant role here. We recently announced a new service called FlexCache. We plan to cache not only report results but also pre-aggregations and significantly reduce the number of queries that must go to the underlying DB engine.
Try It Yourself!
To see GoodData in action, try our free trial.
If you are interested in trying GoodData with MotherDuck, please register for our labs environment here. I also prepared a short DOC page dedicated to MotherDuck here.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product tours


