Whitepapers
Why Agents Will Hallucinate on Your Current Semantic Layer (And the Case for Refactoring)
9 min read | Published


This whitepaper examines why legacy BI architectures lead to AI hallucinations, why traditional migration approaches fail to solve the problem, and how a refactor-first methodology creates the semantic foundation AI agents require.
The "Infinite Transition" Trap
Most BI modernization projects follow a predictable path: rebuild everything, wait 12 to 18 months, and hope for the best. In reality, this approach just shifts effort away from analytics and into infrastructure work. Business logic continues to age, stakeholders lose confidence, and AI initiatives get quietly shelved. This is the infinite transition; years of effort with little to show for it.
Meanwhile, AI adoption is accelerating. According to Box's 2025 State of AI in the Enterprise survey, 87% of companies already use AI agents in at least one workflow. But there's a fundamental problem: you cannot build reliable AI on top of inconsistent business logic.
When metric definitions are scattered across dashboards, SQL, and spreadsheets, AI agents lack the structured foundation they need. Recent benchmarks show hallucination rates for newer AI systems reaching as high as 79%. The root cause isn't the AI models; it is the chaos in your existing BI infrastructure.
Why AI Agents Hallucinate on Your Current BI
The Root Cause: Buried Business Logic
In most organizations, business logic has accumulated over years across multiple systems. A single metric like "customer lifetime value" might be calculated differently in:
- Power BI dashboards (one attribution model)
- Excel spreadsheets (historical averages)
- SQL views (different time windows)
- Legacy reports (deprecated methods)
When an AI agent queries "customer lifetime value," which definition does it use? It can't know, so it guesses. Research confirms that LLMs trained on datasets with high noise levels and inconsistency exhibit higher rates of hallucination. When humans struggle to navigate inconsistent data, AI simply amplifies the confusion.
The Litmus Test
If your team can't explain how a number is calculated, AI won't either.
This isn't theoretical. In 2024, 47% of enterprise AI users made at least one major business decision based on hallucinated content. When business logic is scattered and undocumented, AI agents produce plausible-sounding answers that are fundamentally wrong.
The consequences include:
- Metric fabrication: Creating incorrect calculations that sound reasonable
- Definition drift: Applying inconsistent interpretations of business terms
- Join confusion: Misunderstanding data relationships
- Aggregation errors: Using inappropriate calculation methods
Why Human Analysts Succeed Where AI Fails
Human analysts can reconcile conflicting numbers through judgment and investigation. AI agents cannot. They query a system, trust the response, and generate output. Without a governed semantic layer providing consistent definitions, AI agents will confidently present incorrect analyses.
As industry experts note, trustworthy AI agents require trustworthy foundations. The semantic layer isn't optional for AI deployment.
Why Traditional BI Migration Fails
The Standard Approach: Platform Switching
The conventional wisdom is simple: migrate from your legacy BI tool to a modern platform. Move from Qlik to Power BI. Consolidate Tableau instances. Upgrade to the latest version.
But this approach misses the fundamental issue. Legacy BI platforms share the same architectural limitation: business logic lives embedded inside proprietary files.
When you migrate between platforms, you're moving embedded logic from one proprietary format (.qvf, .pbix, .twb) to another. The tools themselves prevent logic from existing as a separate, governed entity that can be version-controlled, tested, and queried by AI agents.
The Architectural Problem
These platforms were designed for visualization and human-driven analysis, not as semantic foundations for autonomous AI systems. They fundamentally cannot provide logic extraction (business rules trapped in proprietary files), separation of concerns (visual and logic tightly coupled), or engineering workflows (no version control, testing, or CI/CD for business logic).
According to Gartner research, about 40% of infrastructure systems carry significant technical debt, with CIOs reporting that 20%+ of their technical budget gets diverted to resolving tech debt instead of building new capabilities.
The "Lift and Shift" Trap
Standard BI platform migrations follow a predictable pattern: extract dashboard visuals, recreate them in the new tool, manually rebuild data connections, and hope calculations work the same way. This preserves embedded logic, maintains multiple versions of truth, and leaves semantic debt unresolved.
Result: Your AI agents hallucinate just as much on the new platform because the underlying problem (scattered, ungoverned business logic) hasn't been solved.
What About Other "Semantic Layer" Solutions?
Some organizations believe they’ve solved the AI hallucination problem caused by inconsistent business logic by adopting standalone semantic layer tools like dbt Semantic Layer, Cube, or AtScale. These tools represent real progress; they do create governed metric definitions as code.
However, they face a critical limitation: they can’t extract the logic already embedded in your Power BI, Tableau, or Qlik dashboards. They provide a framework for defining metrics going forward, but they don’t recover the years of business logic trapped inside existing BI assets.
This creates a difficult choice: manually rebuild all metric definitions from scratch (taking months and risking errors), or leave legacy dashboards running with embedded logic (perpetuating inconsistency). Neither option addresses the core requirement of AI-ready modernization: extracting, refactoring, and governing existing business logic.
The Refactor-First Alternative
A Different Architectural Pattern
Solving the AI hallucination problem requires a different approach: separate business logic from visualization, then govern it centrally.
This isn't about choosing a different BI vendor. It's about choosing a different architectural pattern where:
- Business logic exists independently of dashboards
- Metrics are defined once and consumed everywhere
- Definitions are version-controlled as code
- AI agents query a governed semantic layer, not individual BI tools
The Four-Phase Refactor Process
Phase 1: AI-Powered Extraction
The first requirement is extracting business logic from proprietary BI files. This means actually reading .pbix, .twb, and .qvf files to pull out:
- Calculation definitions
- Data relationships
- Filter logic
- Metric dependencies
Legacy BI platforms can’t do this for each other; Power BI can’t extract logic from Tableau files, and vice versa. They’re designed to create dashboards for human consumption, not to externalize and govern business logic across tools.
Standalone semantic layer tools face a related limitation. While they provide a framework for defining new metrics as code at the data warehouse layer, they have no ability to parse or extract logic embedded inside proprietary BI artifacts. As a result, they can govern what’s created going forward, but they can’t recover or reconcile the years of business logic already locked inside existing dashboards.
Modern platforms like GoodData use AI to parse these proprietary formats directly and extract embedded business rules, separating calculations from visual presentation. The logic becomes portable, analyzable input rather than trapped tribal knowledge.
Phase 2: Automated Refactoring
Extraction alone isn't enough; you need to clean what you extract. This is where "refactor and shift" differs fundamentally from "lift and shift."
AI agents analyze extracted logic to:
- Identify duplicate metric definitions
- Remove unused calculations
- Consolidate conflicting definitions
- Standardize calculation patterns
- Flag technical debt for review
A typical analysis might discover "Total Revenue" calculated 47 different ways across dashboards, consolidate them into three legitimate variations (gross, net, recurring), and eliminate the other 44 as duplicates or errors.
This cleanup happens during migration, not as a future project that never gets prioritized. Technical debt is reduced as part of the move.
Phase 3: Governed Semantic Layer
Cleaned, consolidated logic is organized into a medallion architecture with a governed semantic layer at its core:
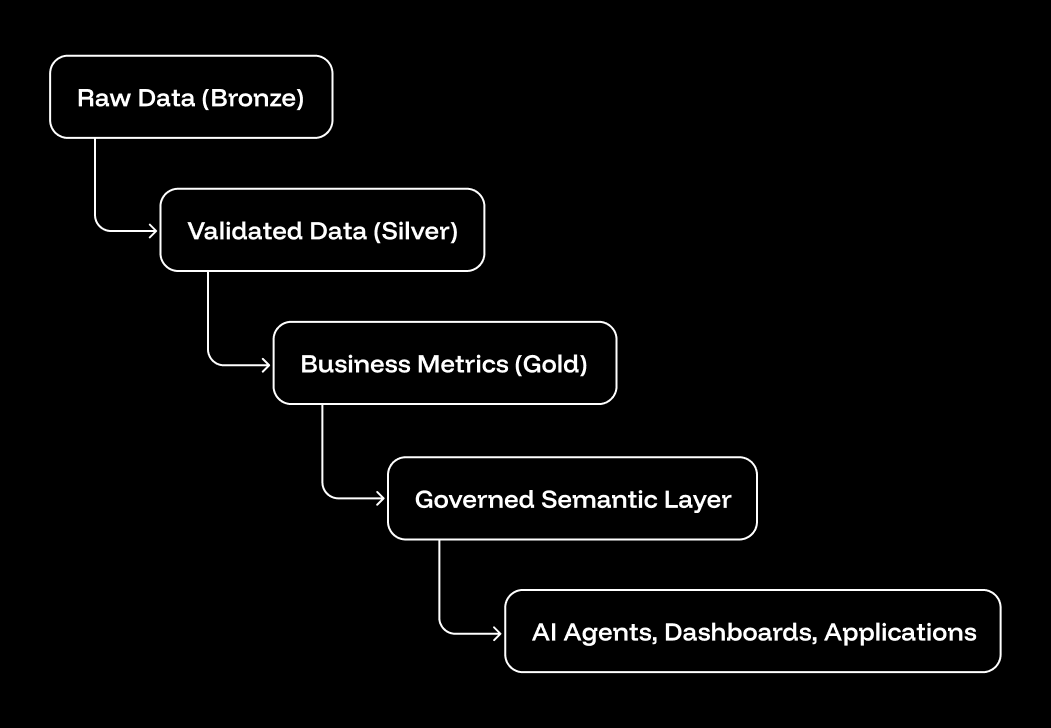
This semantic layer enforces:
- Single definition per metric: "Revenue" means exactly one calculation, used everywhere
- Clear lineage: Complete visibility into how numbers are produced
- Centralized governance: Security and access control defined once, enforced consistently
- API access for AI: Clean, structured interface for autonomous systems to query
When a dashboard, Python script, and AI agent all query "Q4 Revenue," they get the same number, calculated the same way, because they're querying the governed semantic layer rather than individual BI tools.
Phase 4: Analytics-as-Code Deployment
The final phase converts everything to version-controlled, code-based assets. Business logic becomes YAML files managed like software:
metrics:
- name: revenue
* description: Total completed sales revenue*
* type: sum*
* sql: ${orders.amount}*
* filters:*
- ${orders.status} = 'Complete'
This enables:
- Version control: Track every change to metric definitions in Git
- Automated testing: Validate that calculations remain correct
- CI/CD deployment: Review, test, and deploy changes through standard workflows
- Rollback capability: Instantly revert problematic changes
Legacy BI platforms store analytics as binary files that can't be meaningfully version-controlled, tested, or deployed through engineering workflows. This analytics-as-code approach treats BI with the same rigor as software development.
Why This Architecture Enables Reliable AI
This pattern solves the hallucination problem because:
- AI queries governed definitions, not scattered dashboard logic
- Every metric has exactly one authoritative calculation
- Lineage is clear and traceable for validation
- Changes are tested and versioned before deployment
- Logic is portable across visualization tools and AI systems
The semantic layer becomes the single source of truth that AI agents can reliably query without guesswork.
The Migration Path. Fast, Safe, and Proven
Addressing the Migration Fear
One of the biggest barriers to BI modernization isn't technical, but organizational. Employees fear complexity, question value, and resist change. Users who spent years building reports in legacy tools are reluctant to switch without seeing immediate benefit.
This fear is rational. Traditional migrations mean:
- Months of disruption
- Dashboards going offline
- Retraining entire teams
- Risk of losing critical functionality
- Uncertain timeline to value
The refactor-first approach mitigates these risks through parallel operation and incremental migration.
The Methodology
Instead of forcing a cutover, modern platforms like GoodData create a migration bridge that happens in days or weeks, not months:
Phase 1: Assessment
- Connect to legacy BI systems via API
- Extract business logic using AI
- Analyze metric definitions and dependencies
- Identify duplicates, conflicts, and technical debt
- Generate migration inventory and cleanup plan
Phase 2: Refactoring
- Consolidate duplicate definitions
- Resolve conflicting calculations
- Organize logic into medallion architecture
- Convert to version-controlled YAML
- Document lineage and dependencies
Phase 3: Validation
- Deploy semantic layer to the test environment
- Compare outputs against the legacy system
- Investigate any variances
- Achieve 100% match on critical metrics
- Validate with business stakeholders
Phase 4: Deployment & Transition
- Deploy the semantic layer to production
- Keep legacy dashboards running
- Create a new consumption layer
- Enable parallel access to both systems
- Migrate users incrementally, no forced cutover date
The speed advantage: With AI-powered extraction and automated refactoring, what traditionally takes 12-18 months happens in a fraction of the time. Complexity varies by organization, but the methodology remains consistent.
Critical advantage: Dashboards stay online during the transition. Users continue working normally while the foundation gets cleaned up underneath, without disruption.
When Source Systems Won't Cooperate
A common concern is: "What if my legacy BI vendor makes extraction difficult?"
This is where AI-powered platforms prove their value. Legacy vendors intentionally make logic extraction hard to prevent customer departure, trapping business rules in proprietary formats.
Modern extraction engines work around this by:
- Parsing proprietary file formats directly
- Connecting via documented and undocumented APIs
- Analyzing embedded scripts and expressions
- Reconstructing business logic from dashboard behavior
- Using AI to interpret vendor-specific syntax
Even when vendors won't provide clean exports, the logic can be extracted, analyzed, and migrated to a governed semantic layer.
More importantly: if your current BI has poorly documented or missing logic, the refactoring process helps you define it properly. The migration becomes an opportunity to establish governance that never existed before.
The Business Case
Performance and Velocity Gains
Refactoring delivers immediate performance improvements beyond AI readiness:
Faster Dashboards
- Removing inefficient calculations and duplicates reduces query complexity
- Organizations report dashboards loading up to 10× faster
- Reduced compute costs from optimized queries
Faster Development
- Analytics-as-code enables 2-5× faster iteration cycles
- Version control and automated testing reduce rework
- Clear lineage makes impact analysis straightforward
- No more "which dashboard has the right definition?" investigations
Reduced Maintenance
- The governed semantic layer eliminates dashboard-level calculation maintenance
- Single definition updates propagate everywhere automatically
- Technical debt decreases instead of accumulating
The AI Readiness Foundation
The strategic value is enabling reliable AI deployment:
Consistent Outputs
- AI agents query governed definitions instead of guessing
- Hallucination risk drops dramatically when metrics have single, validated definitions
- Trust in AI-generated insights increases
Faster AI Development
- The clean semantic layer accelerates AI use case development
- No need to rebuild data foundations for each AI project
- Reusable, governed metrics serve multiple AI applications
Sustainable AI Scale
- The foundation supports growing AI agent deployments
- New AI use cases consume the existing semantic layer
- Governance prevents quality degradation as AI usage expands
The Cost of Inaction
Staying on legacy BI architecture carries real costs:
Technical Debt Accumulation
- 40% of infrastructure systems already carry significant debt
- More than 20% of the IT budget is diverted to tech debt resolution instead of new capabilities
- Debt compounds over time, making eventual migration harder
AI Initiative Failure
- 47% of enterprise AI users make major decisions based on hallucinated content
- Failed AI projects erode stakeholder confidence
- This creates a competitive disadvantage as others deploy reliable AI agents
Opportunity Cost
- Teams spend time reconciling conflicting metrics instead of generating insights
- There is an inability to deploy AI use cases that competitors are already using
- Slower time-to-market for new analytics capabilities
Why GoodData’s Approach Solves AI Hallucinations at the Semantic Layer
The Architecture-First Philosophy
GoodData was purpose-built for the refactor-first pattern described in this whitepaper. Unlike legacy BI platforms that embed logic in proprietary files, GoodData separates business logic from visualization and governs it centrally.
This architectural difference isn't a feature; it's the foundation of how the platform works.
Lightning-Fast BI Modernization
GoodData's migration methodology addresses every challenge outlined in this whitepaper:
AI-Powered Extraction
- Connects directly to Power BI, Tableau, and Qlik
- Uses AI to extract embedded business logic from proprietary formats
- Separates calculations from visual presentation
- Captures relationships, dependencies, and lineage
Unlike migrating between legacy BI tools (which just moves the problem), GoodData extracts logic into a governed, portable format.
Automated Refactoring
- AI agents identify duplicate metrics across dashboards
- Unused calculations are flagged for removal
- Conflicting definitions are consolidated
- Technical debt is cleaned during migration, not carried forward
This is "refactor and shift" instead of "lift and shift"; you don't move the mess, you fix it.
Governed Semantic Layer
- Organizes cleaned logic using a medallion architecture (Bronze → Silver → Gold → Semantic Layer)
- Provides a single source of truth for every metric with clear lineage
- Enforces centralized governance and access control
- Allows AI agents to query one authoritative definition instead of scattered dashboard logic
Analytics-as-Code Deployment
- All logic is converted to version-controlled YAML files
- Managed in Git with full change history
- Automated testing validates calculations
- CI/CD deployment with instant rollback capability
Dashboards remain operational during transition. Users experience no disruption while the foundation is rebuilt underneath.
The time advantage: Because AI handles extraction and refactoring automatically, GoodData compresses what traditionally takes 12-18 months of manual work into a dramatically shorter timeframe. The exact duration depends on your environment's complexity, but the methodology eliminates the endless migration cycles that trap most organizations.
The Business Impact
Organizations using GoodData's refactor-first approach report:
- 2-5× faster iteration on new analytics development
- Up to 10× performance improvement through optimized calculations
- 60-80% reduction in metric definition conflicts
- Reliable AI deployment without hallucination risks
- Foundation for continuous innovation as analytics-as-code enables rapid evolution
The platform doesn’t just modernize BI; it creates the semantic foundation AI agents require to operate reliably, evolve safely, and scale across the organization.
The entire process is dramatically faster than traditional approaches because AI automates the extraction and refactoring work that would otherwise require months of manual effort. Dashboards stay online. Users continue working. The foundation gets fixed without disruption.
Even when legacy vendors make extraction difficult, GoodData's AI-powered extraction engine works around limitations by parsing proprietary formats directly and reconstructing business logic from dashboard behavior.
For organizations with poorly documented or missing logic, the refactoring process helps establish proper governance during migration, turning a liability into an opportunity.
Conclusion: The Path Forward Starts with Refactoring BI Logic
BI systems didn’t become hard to work with overnight. Over time, business logic was added wherever it was easiest to answer a question. That worked when analytics was mostly consumed by people who understood its limitations.
The underlying assumption no longer holds. Analytics is now reused across applications, workflows, and automated systems. Analytics is now reused across applications, workflows, and automated systems. In that context, scattered, duplicated, or undocumented logic becomes a liability.
Refactoring BI logic during migration addresses this directly. Extracting existing definitions, standardizing them, and governing them centrally makes analytics easier to reason about and safer to change. It also makes reuse possible without relying on tribal knowledge or manual reconciliation.
Teams that take this approach don’t just complete a migration. They leave with a system that can support new use cases without having to repeat the same cleanup work later.
That’s the practical difference between moving dashboards and modernizing BI.
Enjoy this article as well as all of our content.
Trusted by




Does GoodData look like the better fit?
Get a demo now and see for yourself. It’s commitment-free.




