Building Automation Intelligence for Modern Analytics: A Technical Architecture Guide
Executive Summary
Traditional business intelligence systems have reached a critical inflection point. While organizations have invested heavily in dashboards and self-service analytics, the fundamental paradigm remains reactive: users must remember to check dashboards, manually run reports, and actively monitor for changes. This approach creates bottlenecks, delays critical decisions, and fails to scale with modern operational requirements.
As large language models (LLMs) and agentic AI begin to reshape how users interact with analytics — moving away from static dashboards toward conversational and automated interfaces — the need to be proactively alerted to critical changes in data remains essential. Automation intelligence addresses this enduring need by delivering insights precisely when they matter most.
Automation intelligence represents a fundamental shift from reactive to proactive analytics, transforming static dashboards into dynamic, event-driven systems that deliver insights when they matter most. This whitepaper explores the technical architecture, implementation patterns, and engineering considerations required to build robust automation intelligence systems that can operate at enterprise scale.
Table of Contents
- The Evolution from Reactive to Proactive Analytics
- Core Architecture Patterns for Automation Intelligence
- Event-Driven Analytics: Technical Implementation
- Multi-Tenant Automation at Scale
- Context-Aware Delivery Systems
- Performance and Reliability Considerations
- Security and Governance in Automated Systems
- Integration Patterns and API Design
- Future-Proofing: AI and Machine Learning Integration
- Implementation Roadmap and Best Practices
1. The Evolution from Reactive to Proactive Analytics
To understand why automation intelligence is needed, let’s begin by examining the limitations of traditional business intelligence and the shift toward more proactive, event-driven analytics.
The Limitations of Traditional BI Architectures
Traditional business intelligence systems follow a pull-based model where users must actively seek information. This creates several technical and operational challenges:
- Polling Inefficiency: Users repeatedly check dashboards, creating unnecessary load
- Latency in Decision Making: Critical changes go unnoticed until manual review
- Context Loss: Static dashboards lack situational awareness of user roles and needs
- Scaling Bottlenecks: Manual processes cannot scale with organizational growth
The Automation Intelligence Paradigm
Automation intelligence inverts this model, implementing push-based analytics that:
- Triggers on Events: Responds to data changes, threshold breaches, or external signals
- Delivers Contextually: Provides relevant insights based on user roles and permissions
- Integrates Natively: Works within existing workflows and tools
- Scales Automatically: Handles growing users and data volumes without manual intervention
2. Core Architecture Patterns for Automation Intelligence
To deliver proactive insights at scale, a robust architectural foundation is required. This section introduces the key components and design patterns that enable automation intelligence.
2.1 Event-Driven Architecture Foundation
The backbone of any automation intelligence system is a robust event-driven architecture:
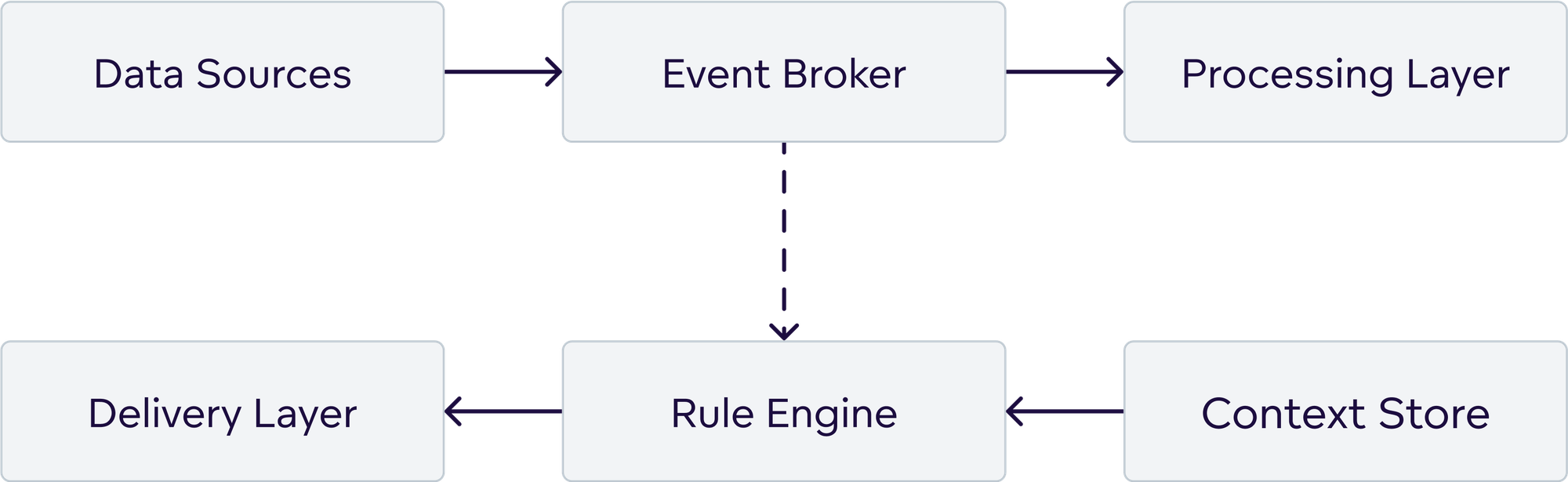
2.2 Key Architectural Components
Event Broker: Handles message routing, persistence, and delivery guarantees
- Message queues (Apache Kafka, RabbitMQ, AWS SQS)
- Event streaming platforms
- Dead letter queues for failed processing
Rule Engine: Processes conditions and triggers actions
- Threshold monitoring
- Pattern detection
- Complex event processing
- Temporal logic evaluation
Context Store: Maintains user preferences, permissions, and delivery settings
- User profiles and roles
- Delivery preferences
- Permission matrices
- Subscription management
Delivery Layer: Handles multi-channel output formatting and transmission
- Email rendering and delivery
- Webhook payload construction
- Export transmission to document storage (e.g., S3, Azure Blob)
- Third-party integration APIs
2.3 Microservices Design Pattern
Automation Intelligence systems benefit from microservices architecture:
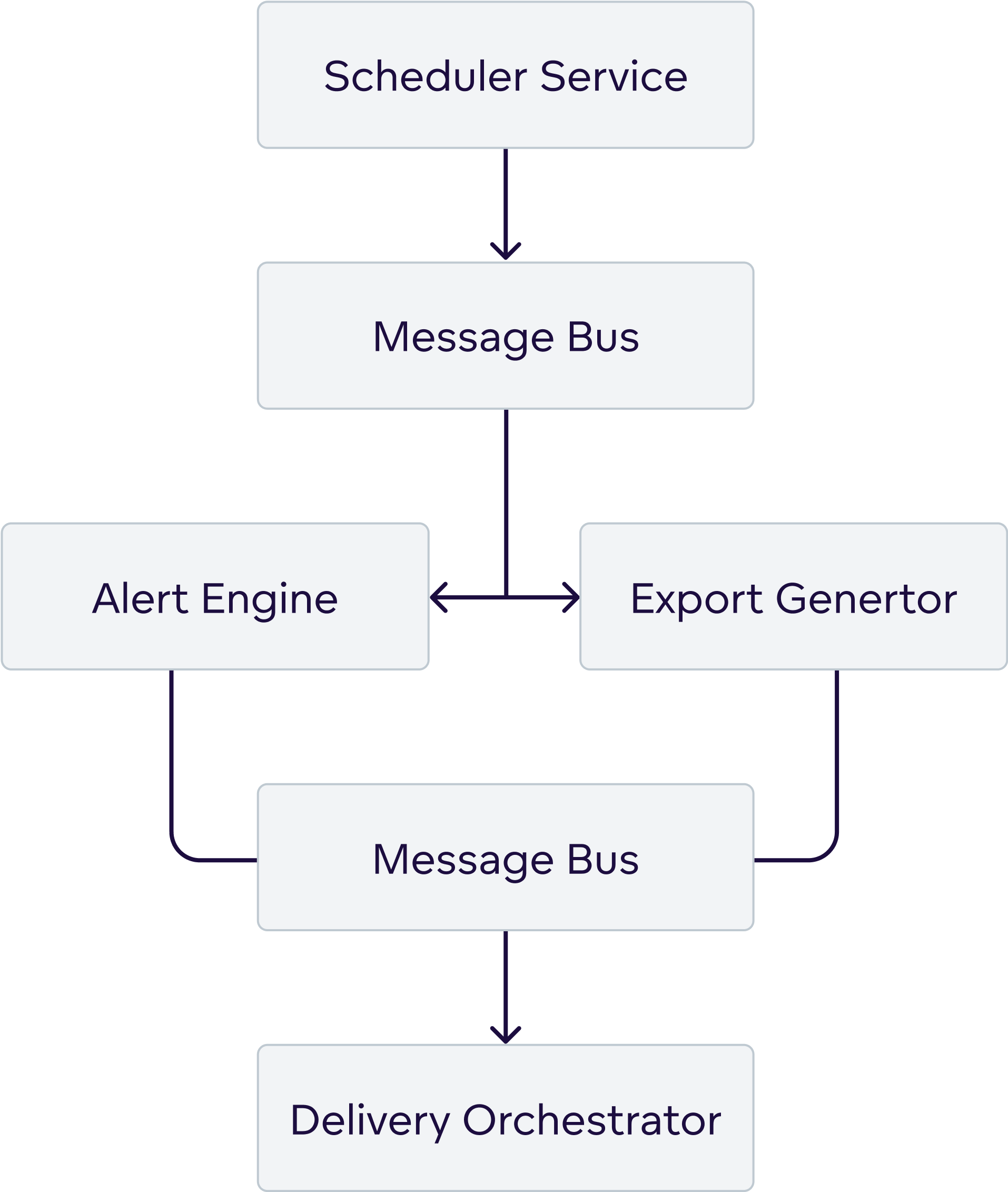
Each service handles specific responsibilities:
- Scheduler Service: Manages time-based triggers
- Alert Engine: Evaluates conditions and generates alerts
- Export Generator: Converts data into requested formats (PDF, CSV, XLSX) and prepares files for delivery
- Delivery Orchestrator: Coordinates multi-channel delivery
3. Event-Driven Analytics: Technical Implementation
With the architectural building blocks in place, the next step is to understand how event-driven automation works in practice, from the types of events to the processing patterns they require.
3.1 Event Types and Sources
Modern automation intelligence systems must handle diverse event types:
Data Events:
- New data ingestion completion
- Data quality threshold breaches
- Schema changes or data anomalies
Metric Events:
- KPI threshold crossings
- Trend changes or inflection points
- Comparative period variations
System Events:
- Scheduled export triggers
- User subscription changes
- System health alerts
External Events:
- API webhooks from external systems
- Calendar-based triggers
- Third-party system status changes
3.2 Event Processing Patterns
Stream Processing: Real-time threshold monitoring requires continuous evaluation of incoming metrics against predefined thresholds. The system must process events as they arrive, compare them to configured thresholds, and immediately trigger alerts when those thresholds are crossed. To support this in a scalable and reliable way, the underlying stream processing architecture must handle challenges such as event ordering, distributed state management, and low-latency processing — all of which are critical for ensuring alert accuracy and responsiveness.
Scheduled Processing: Some automation workflows are time-based, such as scheduled exports or daily summary reports. These are triggered at predefined intervals and submitted as asynchronous jobs to the processing queue. While this may resemble traditional batch processing, modern implementations typically use queuing systems to distribute the workload in parallel. This allows for better scalability and system load management. The export process involves querying the analytics engine, formatting output based on user preferences, and delivering results via configured channels. Robust error handling ensures failed exports are logged and retried independently of successful ones.
3.3 Temporal Event Processing
Many automation scenarios require temporal logic for meaningful insights. Period-over-period alerting compares current metrics against historical values to identify significant changes. This requires maintaining historical context, calculating percentage changes, and applying configurable thresholds to determine when changes are significant enough to warrant notification.
The system must handle various temporal patterns, including seasonal adjustments, business day calculations, and rolling averages. Additionally, robust temporal processing must account for time zones, special calendars (e.g., fiscal years, week start variations), and region-specific holidays, which significantly impact the accuracy and relevance of time-based alerts. These considerations are crucial for ensuring that notifications align with how different teams interpret time-based trends and performance.
4. Multi-Tenant Automation at Scale
Enterprise environments demand strong tenant isolation and operational safeguards. This section explores how automation systems can securely and efficiently support multiple customers or business units.
4.1 Tenant Isolation Strategies
Data Isolation:
- Schema-per-tenant: Complete database separation
- Row-level security: Shared schema with tenant filtering
- Hybrid approach: Critical data separated, operational data shared
Processing Isolation:
- Dedicated worker queues per tenant
- Resource quotas and rate limiting
- Tenant-specific configuration stores
4.2 Subscription Management Architecture
Effective subscription management requires balancing user autonomy with administrative control. The system must track individual user subscriptions while supporting shared automations that multiple users can subscribe to. Key considerations include permission validation, subscription lifecycle management, and handling user preferences.
The architecture must support both individual and group subscriptions, with proper handling of user context and filtering. When users subscribe to shared automations, the system must ensure they receive appropriately filtered content based on their roles and permissions. Subscription changes should be immediately reflected in delivery manifests without disrupting ongoing operations.
Some systems also support external recipients; users who receive content via email without having an authenticated account. This introduces additional security and permission challenges, including how to determine what data can be safely delivered and whether such recipients should be allowed at all. Supporting this model requires strict controls on content filtering, masking, and delivery validation.
4.3 Context-Aware Filtering
Multi-tenant systems must ensure each user receives appropriately filtered content based on their role, permissions, configured filters, and row-level security policies. Role-based filtering applies organizational hierarchy rules, while user-defined filters provide personalized data views. Permission-based column filtering ensures sensitive information is only visible to authorized users.
The filtering system must operate efficiently at scale, applying multiple filter layers without significantly impacting performance. Pre-computed filter indexes and caching strategies help maintain responsiveness while ensuring data security and relevance.
5. Context-Aware Delivery Systems
To ensure automated insights are useful, they must be delivered in context. This section covers the mechanisms for tailoring content to user roles, preferences, and delivery channels.
5.1 User Context Resolution
Context-aware delivery requires comprehensive user profiling that encompasses roles, permissions, filters, delivery preferences, and localization settings. The system must efficiently resolve user context at delivery time, considering both static user attributes and dynamic session information.
Context resolution involves aggregating data from multiple sources: user profiles, role definitions, permission matrices, and preference settings. The resolved context must be cached appropriately to avoid performance bottlenecks while ensuring real-time updates when user attributes change.
5.2 Dynamic Content Personalization
Personalization goes beyond simple filtering to include adaptive content generation based on user roles and preferences. Executive users might receive high-level summaries with key insights, while operational users need detailed data tables and actionable recommendations.
When generating content, the personalization engine must consider user context, data significance, delivery format, user preferences, and past interactions. This includes selecting appropriate visualizations, adjusting detail levels, and highlighting relevant insights based on the user's responsibilities and interests.
5.3 Multi-Channel Delivery Architecture
Multi-channel delivery requires a flexible orchestration layer that can format content appropriately for different delivery mechanisms while maintaining a consistent user experience. Each channel has unique requirements for formatting, authentication, and error handling.
The delivery orchestrator must handle channel-specific formatting, manage delivery preferences, and provide comprehensive logging for audit and troubleshooting purposes. Failed deliveries should be retried with appropriate backoff strategies, and permanent failures should trigger alternative delivery methods when configured.
6. Performance and Reliability Considerations
Automation at scale must be resilient and performant. The following section outlines strategies for ensuring reliability, optimizing throughput, and monitoring system behavior.
6.1 Scalability Patterns
Horizontal Scaling:
- Stateless processing services
- Load balancing across worker nodes
- Auto-scaling based on queue depth
Vertical Scaling:
- Resource-intensive operations (PDF generation, complex queries)
- Memory optimization for large datasets
- CPU optimization for computation-heavy tasks
6.2 Reliability and Fault Tolerance
Retry Mechanisms: Robust retry strategies must distinguish between transient and permanent failures. Transient failures (network timeouts, temporary service unavailability) should trigger exponential backoff retries, while permanent failures (invalid credentials, deleted resources) should not be retried. The system must track retry attempts and escalate persistent failures to administrators.
Circuit Breaker Pattern: In parts of the system that rely on synchronous communication (e.g., REST APIs between services), circuit breakers prevent cascading failures by temporarily halting requests to a failing service. When a service exceeds error thresholds, the circuit breaker opens to block further calls, and after a timeout, it enters a half-open state to test recovery.
In asynchronous, message-driven parts of the system, queuing mechanisms and backpressure provide similar resilience by decoupling services and handling failures through retries and dead-letter queues.
6.3 Performance Monitoring and Optimization
Key Metrics:
- Delivery latency (end-to-end)
- Processing throughput
- Error rates by channel and by cause (e.g., user misconfiguration vs. system failure)
- Resource utilization
Optimization Strategies:
- Query result caching
- Pre-computed aggregations
- Asynchronous processing
- Resource pooling
7. Security and Governance in Automated Systems
Automation must adhere to the same rigorous security and compliance standards as core data platforms. This section details authentication, access control, and data protection strategies.
7.1 Authentication and Authorization
Service-to-Service Authentication: Microservices architectures often require secure communication between internal services. In distributed environments, this is commonly implemented using JWT tokens with service-specific scopes, validated using shared secrets or public key infrastructure. In message-driven architectures or trusted internal networks, service communication may instead be brokered through a secure message bus or orchestrated behind an API gateway, reducing the need for explicit per-service authentication.
User Permission Validation: User permissions must be validated at multiple layers: API access, automation creation, and content delivery. The system should implement role-based access control (RBAC) with hierarchical permissions that cascade through organizational structures. Permission validation must be efficient to avoid impacting user experience while maintaining security.
7.2 Data Privacy and Compliance
Data Protection and Access Control: Rather than relying heavily on data masking, modern automation systems enforce data privacy primarily through strict access control mechanisms such as row-level security and permission-based filtering. These ensure users only receive data they are authorized to view across all delivery channels. In export workflows, additional precautions may be required — such as isolating browser-based rendering environments behind secure proxies — to prevent sensitive information from being inadvertently cached or exposed during visual export generation.
Audit Logging: Comprehensive audit logging tracks all automation activities, including creation, modification, execution, and delivery. Audit logs must capture user identity, actions performed, data accessed, and delivery outcomes. This information supports compliance requirements and enables security monitoring and incident investigation.
7.3 Secure Delivery Channels
Email Security:
- SPF/DKIM/DMARC implementation
- TLS encryption for transmission
- Secure attachment handling
Webhook Security:
- HMAC signature verification
- SSL/TLS requirement
- Rate limiting and IP whitelisting
8. Integration Patterns and API Design
To maximize value, automation systems must integrate seamlessly with external tools and workflows. This section presents API and integration patterns that enable extensibility.
8.1 RESTful API Design
Automation management APIs should follow RESTful principles with clear resource hierarchies and consistent error handling. Key endpoints include automation creation, configuration management, execution triggering, and status monitoring. The API should support both synchronous operations for immediate feedback and asynchronous operations for long-running processes.
Authentication and authorization must be consistent across all endpoints, with proper rate limiting to prevent abuse. API versioning strategies ensure backward compatibility while enabling the evolution of automation capabilities.
8.2 Webhook Integration Patterns
Webhook delivery requires robust security and reliability mechanisms. Authentication headers and cryptographic signatures ensure message integrity and source verification. The system must handle webhook failures gracefully with configurable retry policies and dead letter queues for persistent failures.
Webhook payload formats should be standardized while allowing customization for specific integration requirements. Rate limiting prevents overwhelming downstream systems, and comprehensive logging enables troubleshooting integration issues.
8.3 Third-Party Integration Examples
Slack Integration: Slack delivery requires proper bot authentication and channel management. The system must format content using Slack's Block Kit for rich visual presentation. Message threading and user mentions enable interactive features that enhance user engagement with automated insights.
Microsoft Teams Integration: Teams integration leverages Adaptive Cards for rich content presentation. Webhook-based delivery provides reliable message delivery, while Teams-specific formatting ensures optimal user experience within the collaboration platform.
Shared Drive Integrations (e.g., S3, Azure Blob, GCS): Many automation workflows involve exporting reports or audit trails to cloud-based storage services. These integrations are particularly useful for long-term archiving, regulatory compliance, or offline access by external systems. Proper configuration of access permissions is critical — misconfigured storage buckets are a common source of data exposure. Best practices include restricting public access, using IAM roles or signed URLs, and monitoring access logs for unusual activity.
9. Future-Proofing: AI and Machine Learning Integration
The future of automation intelligence lies in AI-driven insights. This section explores how machine learning enhances anomaly detection, personalization, and decision support.
9.1 Anomaly Detection Integration
Anomaly detection systems use machine learning models to identify unusual patterns in metrics and data. Integration requires standardized interfaces for model deployment, feature preparation, and result interpretation. The system must handle model versioning, A/B testing, and performance monitoring to ensure reliable anomaly detection.
Confidence scoring helps filter false positives while ensuring genuine anomalies trigger appropriate alerts. The system should support multiple detection algorithms and allow customization of sensitivity levels based on business requirements.
9.2 Predictive Alerting
Predictive alerting uses forecasting models to anticipate future threshold breaches or significant changes. This proactive approach enables preventive actions rather than reactive responses. The system must integrate forecasting models with confidence intervals and prediction horizons appropriate for business decision-making.
Predictive alerts should include context about the forecast methodology, confidence levels, and recommended actions. The system must handle model drift and retraining requirements to maintain prediction accuracy over time.
9.3 Natural Language Processing for Automation
Natural language processing enables users to create and manage automations using conversational interfaces. The system must parse user intents, extract relevant entities, and translate natural language requests into automation configurations. This capability significantly reduces the technical barrier to automation adoption.
NLP integration requires training data specific to automation domain vocabulary and continuous improvement based on user interactions. The system should handle ambiguous requests gracefully and provide clarification prompts when needed.
9.4 Key Driver Analysis and Smart Recommendations
While anomaly detection highlights that something has changed, key driver analysis (KDA) provides insight into why the change occurred. KDA leverages machine learning to identify the variables that most significantly contributed to an anomaly or metric shift, helping users understand the root causes behind threshold breaches or performance fluctuations.
This capability enhances trust and transparency in automated alerting by surfacing explainable insights. In addition, smart recommendation engines can suggest appropriate next steps based on historical outcomes, business rules, or predictive models — transforming raw detection into actionable intelligence. Recommendations might include suggested actions, impacted stakeholders, or links to operational workflows.
Together, KDA and recommendation systems represent the next evolution of automation intelligence — moving from alerting to guided decision-making.
10. Implementation Roadmap and Best Practices
Building a production-grade automation system requires careful planning and iteration. This final section outlines a phased implementation plan and proven best practices.
10.1 Phase 1: Foundation (Weeks 1-4)
Core Infrastructure:
- Set up event-driven architecture
- Implement basic scheduling service
- Create user context management
- Build simple email delivery
Key Deliverables:
- Event broker implementation
- Basic automation API
- User authentication system
- Email delivery service
10.2 Phase 2: Core Features (Weeks 5-12)
Advanced Automation:
- Threshold-based alerting
- Multi-channel delivery
- Subscription management
- Export generation
Key Deliverables:
- Alert engine with rule processing
- Webhook and Slack integration
- PDF/Excel export generation
- Subscription management UI
10.3 Phase 3: Scale and Intelligence (Weeks 13-20)
Enterprise Features:
- Multi-tenant support
- Advanced permissions
- Audit logging
- Performance optimization
Key Deliverables:
- Tenant isolation architecture
- RBAC implementation
- Comprehensive audit trails
- Performance monitoring
10.4 Phase 4: AI Enhancement (Weeks 21-28)
AI Integration:
- Anomaly detection
- Predictive alerting
- Natural language processing
- Intelligent scheduling
Key Deliverables:
- ML model integration
- Anomaly detection service
- NLP automation parser
- Predictive alert engine
10.5 Best Practices and Lessons Learned
Architecture Principles:
- Design for failure: Implement comprehensive error handling
- Plan for scale: Use horizontal scaling patterns from day one
- Security first: Implement security at every layer
- Monitor everything: Comprehensive observability is crucial
Operational Excellence:
- Implement comprehensive testing strategies
- Use infrastructure as code
- Automate deployment pipelines
- Plan for disaster recovery
User Experience:
- Prioritize intuitive configuration interfaces
- Provide clear error messages and debugging tools
- Implement self-service capabilities
- Focus on reliability over features
Conclusion
Automation Intelligence represents a fundamental shift in how organizations consume and act on data insights. By implementing the architectural patterns and technical strategies outlined in this whitepaper, engineering teams can build robust, scalable automation systems that transform reactive business intelligence into proactive operational intelligence.
The key to success lies in thoughtful architecture that prioritizes scalability, security, and user experience while maintaining the flexibility to integrate with existing systems and adapt to future requirements. As AI and machine learning capabilities continue to evolve, organizations with strong automation intelligence foundations will be best positioned to leverage these advances for competitive advantage.
The transition from manual, dashboard-centric analytics to automated, context-aware insight delivery is not just a technical upgrade but a strategic imperative for organizations that want to operate at the speed of modern business.
GoodData's Automation Intelligence: A Comprehensive Implementation
While the architectural patterns described in this whitepaper provide a foundation for building automation intelligence systems, implementing these capabilities from scratch requires significant engineering investment and ongoing maintenance. GoodData's Automation Intelligence offers a production-ready platform that embodies these principles while providing additional capabilities that accelerate time-to-value.
Built-in Automation Architecture
GoodData's platform implements the event-driven architecture patterns discussed throughout this whitepaper with a focus on embedded, multi-tenant deployment. The system provides:
No-Code Automation Creation: Users can create scheduled exports and metric-based alerts directly from dashboards without requiring technical expertise or custom development. This eliminates the traditional barrier between business users and automation capabilities.
Context-Aware Delivery: The platform automatically applies user permissions, role-based filtering, and personalization rules to ensure recipients receive relevant, secure content. User Data Filters (UDFs) and organizational hierarchies are seamlessly integrated into the automation delivery pipeline.
Multi-Channel Distribution: Automations can deliver content via email, Slack, webhooks, and file exports (PDF, XLSX, CSV), with each channel optimized for its specific use case. The system handles channel-specific formatting, authentication, and error handling automatically.
Scalable Multitenancy: Built from the ground up for embedded analytics use cases, the platform supports tenant isolation, resource quotas, and independent automation management across multiple customer environments.
Advanced Automation Capabilities
Threshold and Period-Based Alerting: The platform supports sophisticated alerting logic, including metric thresholds, period-over-period comparisons, and attribute-level monitoring. Alert conditions can be configured with complex rules that accommodate business logic and seasonal patterns.
Subscription Management: Users can subscribe to shared automations or create personal copies with their own configurations. The system handles subscription lifecycle management, permission validation, and delivery preference updates automatically.
Workflow Integration: REST APIs, webhooks, and Python SDKs enable end-to-end integration of automation capabilities into existing workflows and custom applications. APIs and SDKs support the programmatic creation, configuration, and management of automations, while webhooks enable the real-time push of automated insights and exports into external systems.
Enterprise Governance: Role-based permissions control who can create, modify, and manage automations at both personal and organizational levels. Comprehensive audit logging tracks all automation activities for compliance and security monitoring.
AI-Powered Automation on the Horizon
GoodData is actively developing AI-enhanced automation capabilities that will further reduce manual effort and increase insight relevance:
Anomaly Detection: Machine learning models will automatically detect unusual patterns in metrics and trigger intelligent alerts without requiring manual threshold configuration. This capability will reduce false positives while ensuring genuine anomalies receive immediate attention.
Predictive Alerting: Forecasting models will identify potential future issues before they impact business operations, enabling proactive rather than reactive decision-making. Predictive alerts will include confidence intervals and recommended actions based on historical patterns.
Natural Language Scheduling: Conversational interfaces will enable users to create and manage automations using natural language commands, such as "Send me a weekly sales report every Monday at 9 AM" or "Alert me when customer satisfaction drops below 85%."
Intelligent Insights: AI will automatically generate contextual insights and recommendations based on data patterns, user behavior, and business context, transforming plain notifications into actionable intelligence.
Production-Ready Reliability
GoodData's platform implements the reliability patterns discussed in this whitepaper with enterprise-grade operational capabilities:
Fault Tolerance: Circuit breakers, retry mechanisms, and graceful degradation ensure system resilience during failures. Failed deliveries are automatically retried with exponential backoff. For persistent failures, the system can trigger pre-configured fallback delivery methods — such as switching from email to webhook or saving the output to shared storage — to ensure insight delivery is not disrupted.
Performance Optimization: Query result caching, pre-computed aggregations, and intelligent resource management ensure consistent performance as automation usage scales. The system optimizes delivery timing to minimize resource contention and maximize throughput.
Security and Compliance: End-to-end encryption, comprehensive audit logging, and robust data isolation support regulatory compliance requirements. The platform enforces security best practices throughout the automation pipeline, including built-in row-level security and permission-based access controls to ensure that users only access data they are authorized to see.
Monitoring and Observability: Built-in monitoring tracks automation performance, delivery success rates, and system health metrics. These insights are used internally to ensure platform reliability and to support operational diagnostics and incident resolution.
Temporal Complexity: Handling time zones, fiscal calendars, and locale-specific schedules is another often-overlooked challenge. Production-ready platforms must support accurate scheduling and insight delivery across global teams, a capability that is extremely difficult to build and maintain from scratch.
Getting Started with Automation Intelligence
Organizations looking to implement automation intelligence can accelerate their journey by leveraging GoodData's proven platform rather than building capabilities from scratch. The platform's embedded architecture makes it particularly well-suited for:
- SaaS Applications: Embed automation capabilities directly into customer-facing applications
- Enterprise Analytics: Provide scalable automation for large organizations with complex permission structures
- Operational Intelligence: Transform business operations with real-time, context-aware insight delivery
- Customer Analytics: Enable external users to receive automated insights without system access
The combination of comprehensive automation capabilities, AI-powered enhancements, and production-ready reliability makes GoodData's Automation Intelligence platform an ideal foundation for organizations ready to transform their analytics from reactive to proactive.
This whitepaper provides a comprehensive technical foundation for building automation intelligence systems. GoodData's Automation Intelligence features implement these architectural patterns with additional enterprise capabilities, AI enhancements, and production-ready reliability. To learn more about how GoodData can accelerate your automation intelligence journey, visit gooddata.com or contact our technical team for a detailed architectural discussion.
Continue Reading This Article
Enjoy this article as well as all of our content.
Does GoodData look like the better fit?
Get a demo now and see for yourself. It’s commitment-free.
Trusted by