Relational and Dimensional Data Models
6 min read | Published

Summary
This article compares two common approaches to structuring data for analytics: relational models and dimensional models. It explains how relational models prioritize data integrity and work well for operational systems, while dimensional models focus on faster querying and reporting through simplified structures such as star, snowflake, and galaxy schemas. It also outlines how GoodData supports both approaches, helping teams choose the right model based on whether their needs are more transactional or analytical.
Introducing Data Models
A data model is an abstract model that helps to organize data elements and standardize how they are related. It reveals relationships between different real-world objects. It also refers to an output of data modeling: a process of creating visual diagrams using different components to represent the data.
To review the basics of data models as well as learn about the process of building data models and how GoodData supports this process, read our article “What Is a Data Model?”
Now, let's look at some examples of data models, paying special attention to today's most used types — relational and dimensional data models — in order to highlight their use cases and benefits.
What Is a Relational Data Model?
A relational data model is an approach to creating relational databases in order to manage data logically by its structure and language consistency. In this model, data is represented in the form of two-dimensional tables. Each table represents a relation of data values based on real-world objects, consisting of columns and rows known as attributes and tuples.

A table represents a relation of data values based on real-world objects.
Relational data models prioritize the maintenance of data integrity. This practice ensures data protection and consistency which are critical aspects of data model design, its implementation, and its future usage for storing, processing, and retrieving data.
How to Build a Relational Data Model
While building a relational data model, you can define all types of relationships between relations representing real-world objects, such as one-to-one, one-to-many, and many-to-many. Many-to-many relationships require decomposition, which refers to a process of dividing a relationship into two or more sub-relations. This process creates an additional table with two one-to-many sub-relationships connected to the main tables. The connections between tables in relational databases are made by relational references using primary and foreign keys.
There are three types of keys in a relational data model:
- Primary: A primary key identifies a particular row in a database table.
- Foreign: A foreign key refers to the primary key of another table.
- Candidate: A candidate key can be selected and used as the primary key.

Examples of keys
Image credit: Guru99
Another essential step of building relational data models is normalization. Normalization is a process of analyzing relation schemas based on functional dependencies and relational references in order to decrease redundancy and avoid anomalies. There are several normal forms (NF) but the first three are the most common:
- 1NF (atomicity): Relation is in 1NF if the domain of each attribute contains atomic values. For example, we could mention customers' addresses. Each address consists of the street name and number, city, and postal code. To meet 1NF, it's necessary to keep them as separate attributes. The following example has two attributes: Full Name and Address. To meet 1NF in this example, we must split the attribute Full Name into First Name and Last Name, and Address into Street and City.

Splitting attributes
- 2NF: Relation is in 2NF if it is in 1NF and each non-key attribute must depend on the entire primary or candidate key based on duplicity elimination in the current relation. For example, there is a relation related to students and it not only stores information about each student, but also contains information about school (e.g., faculty name, address, or contact information), which is not related to students. In this situation, it is mandatory to clarify which attributes relate to students versus school, and then accordingly divide one table into two separate tables.

Dividing a table into two separate tables.
- 3NF: Relation is in 3NF if it is in 2NF and does not have a transitive dependency. Meaning, if attribute X depends on attribute Y, and attribute Y depends on attribute Z, then attribute X should not depend on attribute Z. If this situation exists, splitting the table into at least two individual tables may be a good solution. As an example, we used the table from the previous example before it was split into two separate tables. In this case, the relation between student and school is still kept.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product toursWhat Is a Dimensional Data Model?
A dimensional data model is a type of database used for data warehousing and online analytical processing. This model is a part of the core architectural foundation of developing highly optimized and effective data warehouses in order to create useful analytics. It provides users with denormalized structures for accessing data from a data warehouse.
How To Build a Dimensional Data Model
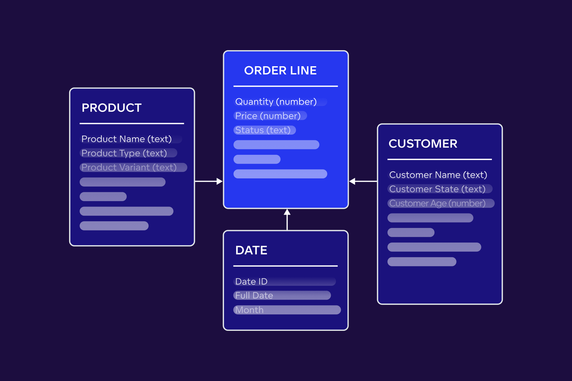
A dimensional data model consists of two types of tables: fact tables and dimensional tables. A fact table stores numeric information about different business measures. Dimensional tables, also known as dimensions, store attributes used to describe objects in a fact table. A dimension is a set of reference information about a measurable event in data warehousing. Primary and foreign keys connect fact tables and dimensions as they do in relational data models.
You can build your dimensional data model based on different schemas: star, snowflake, or galaxy. In the center of every star schema is a fact table containing measures and foreign keys of connected dimensions.

Star schema example
A snowflake schema extends a star schema and contains some additional dimensions. Dimensional tables are standardized and normalized, resulting in dimensions split into extra tables which are reconnected in hierarchical order.
A galaxy schema is similar to the above mentioned schemas, but it has more than one fact table. It usually contains at least two fact tables from two separated dimensional models which share the same dimensional table.

Galaxy schema example
To design dimensional data models, denormalization is the best approach. Denormalization is a process which is usually applied on top of a normalized database/data model. It is done by adding data duplicates or grouping data. Denormalization is necessary to increase performance and support scalability due to the fact that this data model deals with a large number of read operations/queries for analytics purposes.
Relational Data Models vs. Dimensional Data Models
Relational data models differ from dimensional data models in many ways: the process of data modeling, use cases, benefits, and drawbacks.
Importance and Use Cases
Relational data models store present data. Their primary purpose is to model relational databases, which are especially useful to establishing and managing an overview of current data. Relational data models can support operations for various industries. Banks can use them to store sensitive data about customers' accounts, just as vendors can use them to store available items on their e-commerce store. Relational databases are used to read and write data.
Dimensional data models are designed to store historical data for analytics purposes and create data warehouses. You can use them to store data (regardless of the department or use case it's related to) that was gained by tracking different processes, such as products sold, numbers of visitors, etc. Data warehouses created in dimensional data models are mostly used to read data.
Advantages and Disadvantages of a Relational Data Model
Advantages:
- Data is located in a single data store. It enables each department to pull data from the same source rather than having separate data sources.
- By normalizing data, you can maintain the integrity and accuracy of tables in your data/database model. Accuracy eliminates the possibility of data duplication by connecting relations with primary and foreign keys. Integrity helps to ensure reliability between relations (to avoid imperfect and isolated records) as well as simplicity, stability, and precision of the data.
- This model is highly secure. You can limit users' access by enabling them to interact with only certain tables that are relevant to their work.
Disadvantages:
- Relational data models may begin to seem complex as the amount of data stored in them increases and its relationships become more complicated. Additionally, longer response time while querying may occur as a result of the need to join many tables and process all the data.
- When using a live system environment, running a new query — especially one that includes DELETE, ALTER TABLE, or INSERT — can be risky. Minor errors can affect the entire system, resulting in lost time and decreased performance.
Advantages and Disadvantages of a Dimensional Data Model
Advantages:
- Dimensional data models allow you to connect data from different data sources.
- With dimensional data models, performance is increased and response time is decreased due to denormalization and fewer joins between relations in comparison to relational data models. Similar data is grouped in one dimension.
- This type of data model can be easily set up for real-time analytics purposes.
- The structure of dimensional data models helps you to better understand your business processes. Information is stored in dimension tables as attributes, and fact tables contain measures.
Disadvantages:
- Designing and managing dimensional data models may require more professional skills and the ability to understand and analyze a large capacity of data.
Data Models in GoodData
GoodData provides users with an analytical platform and enables them to connect data from multiple sources, create various metrics, and design dashboards to track business performance.
With GoodData, you can create dimensional data models that meet your needs and preferences. By creating dimensional data models, you can design a database to store various data in a centralized place, then design your data in a way that works best for you. It allows and supports faster data retrieval and helps create valuable reports to improve and facilitate future business decision-making.
Additionally, GoodData supports dimensional models based on any kind of dimensional schema. You can choose from a star, galaxy, or snowflake schema as we mentioned above.

One way to create a dimensional data model in GoodData is through the LDM Modeler.
Ready To Get Started?
Try out our GoodData.CN Community Edition and create data models to track your business processes. Connect sources, create metrics, and design dashboards according to your requirements. Additionally, don't forget to complete this GoodData University Course to learn more about GoodData's solution and read our documentation.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product toursIf you are interested in GoodData.CN, please contact us. Alternatively, sign up for a trial version of GoodData Cloud: https://www.gooddata.com/trial/
FAQ About Relational and Dimenisonal Data Models
Relational models maintain data integrity through normalization and structured relationships like primary and foreign keys, ensuring reliable transaction processing and consistency.
Dimensional models use fact and dimension tables that simplify querying and make it easier to aggregate data, resulting in faster performance for reports and dashboards.
They reduce the need for complex joins, which speeds up queries and improves responsiveness in analytics environments that require quick access to large datasets.
Dimensional models often reflect business concepts and metrics in a way that is easier for nontechnical users to explore, understand, and act on.
Dimensional models intentionally denormalize data to simplify queries and improve performance. This design choice favors query speed over storage efficiency, which is often a worthwhile trade-off in analytics contexts