Build a Headless BI Stack on Top of PostgreSQL
4 min read | Published


Your data stack is only as strong as its weakest link
PostgreSQL is one of the most popular open-source databases in the world, and there is good reason for so many having chosen it as a basis for their analytics solution. PostgreSQL comes with many features aimed to help developers build applications, administrators protect data integrity and build fault-tolerant environments, and help you manage your precious data.
All this makes PostgreSQL a sound option for those choosing a database for their analytics. But PostgreSQL is only one cog in your data stack, and its benefits are of no use if the rest of the stack cannot move you beyond traditional analytics. And this is where a powerful headless BI engine comes into play.
Headless BI — a decoupled API-based data stack
Imagine defining all of your metrics in one place, and then using them seamlessly, anywhere you want, with any application or consumer. This is the core of headless BI but, unfortunately, the outdated BI tools currently used are unable to implement this new framework.
The old monolithic tools aren’t able to decouple the analytical calculations and formulas from data visualization and consumption. This leads to a situation where key metrics like revenue and profit have three different definitions that yield three different numbers. And making matters worse, business stakeholders tend to change the metric definitions when requirements and use cases change. Thus, the maintenance and synchronization of these calculations, which are defined in different technology stacks by different teams, is simply impossible. The same goes for managing consistent data access across all the different tools and platforms your current data stack is using.
The end result, as we are all painfully aware, is that end users see different, inconsistent numbers, trends, KPIs, and forecasts. And because of this, your applications and machine learning models work with incorrect data, resulting in ill-informed decisions and, subsequently, the wrong business actions taken by your analytics consumers.

Legacy data stack
Headless analytics solves this inconsistency obstacle by decoupling and sharing measures, the semantic data model, data access permissions, and related metadata. When all these shared objects are available to data visualization, machine learning models, and data-driven applications via open APIs and standards-based protocols, your analytics consumers can always utilize consistent data, metrics, and insights. In a nutshell, you just define and manage all of your metrics in one place, and then share them seamlessly with anyone, anywhere.

Headless BI stack
Cloud-native headless BI engine
GoodData.CN (Cloud-native) is our implementation of the headless BI engine. It exposes the consistent metrics layer and rich semantic model capabilities, like powerful and user-friendly query language, and real-time and data streaming capabilities, via open API and standards-based data protocols. It is designed to be API first and it supports declarative definitions of all objects and aspects of the analytical solution enabling you to automate and version your whole analytics experience.
To ensure the scalability and deployment flexibility of your analytics, GoodData.CN has been engineered to scale with microservices, and to be deployed anywhere. You decide how, where, and when your analytics are executed. Deploy it in containers next to your data in the public cloud, (like Amazon AWS, Microsoft Azure, and Google GCP), private cloud, or within an on-premises datacenter.
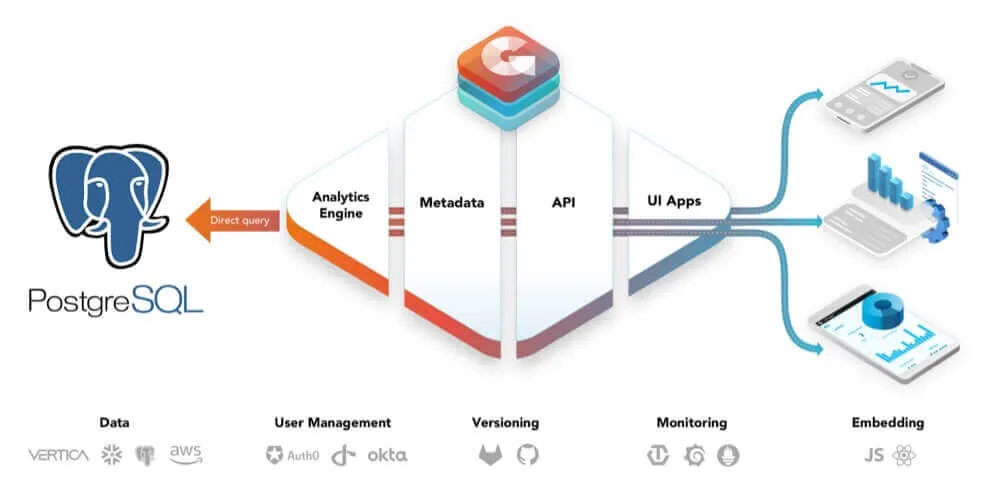
Connecting PostgreSQL to GoodData
To connect PostgreSQL to GoodData.CN, you create the data source using an API call. You can use Postman, curl, or the GoodData.CN API console (/apidocs/) for invoking the APIs. After you create the data source, the platform scans the database, transforms its metadata to a declarative definition of the physical data model (PDM), and stores the PDM under the data source entity. You then generate a logical data model (LDM) from the stored PDM. With GoodData.CN, the analytical engine queries your PostgreSQL database directly, enabling real-time analytics use cases.
Example: A sample request body to be submitted to /api/entities/dataSources for creating a PostgreSQL data source:
{
"data": {
"attributes": {
"name": "demo-ds",
"url": "jdbc:postgresql://localhost:5432/demo",
"schema": "demo",
"type": "POSTGRESQL",
"username": "demouser",
"password": "demopass",
"enableCaching": false
},
"id": "demo-ds",
"type": "dataSource"
}
}
For a more comprehensive tutorial, check out this article on how you can create embedded, self-service analytics on top of your Postgres data with GoodData.CN.
You can also connect your PostgreSQL to GoodData’s hosted platform, and use the platform’s intuitive UI to establish the connection. The connection extracts consolidated and cleaned data directly from your PostgreSQL database, and distributes it to your workspaces. With this approach, the analytical queries are not sent directly to PostgreSQL, but to specific workspaces where your data was loaded. This ensures data privacy and enables you to easily scale, distribute, and manage data, dashboards, and insights between different types of end users and use cases.
Read more about how to connect PostgreSQL to the hosted platform here: GoodData-PostgreSQL Integration Details.
PostgreSQL + GoodData — Get the best of both worlds
When you integrate your PostgreSQL database with GoodData, you get the best of both worlds — the world’s most advanced open-source relational database, and a powerful headless analytics engine that gives you the flexibility to build and scale any of your data use cases. This flexibility allows you to streamline your analytics for all your users — internal and external — to query, explore, and discover.
Would you like to build apps like SF Traffic Accidents Demo, where CleverMaps combines PostgreSQL as a data warehouse database with their location intelligence platform and GoodData.CN into one storytelling website? With GoodData-PostgreSQL integration and GoodData.UI, GoodData’s free React-based JavaScript library, you can integrate your analytics as a native part of your application, creating a seamless analytics experience for your end users.
Try it for yourself
Do you have your data in PostgreSQL and want to utilize the headless BI framework to distribute consistent data analytics and visualizations for all your teams, customers, and partners? Check out our cloud-native analytics platform, and start discovering, for free, how seamless building a powerful headless BI stack on top of your PostgreSQL can be.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product toursIf you are interested in GoodData.CN, please contact us. Alternatively, sign up for a trial version of GoodData Cloud: https://www.gooddata.com/trial/




