How GoodData Integrates With dbt
5 min read | Published


Welcome to our new article! 👋 We will demonstrate how to quickly and efficiently integrate dbt with GoodData using a series of Python scripts. In the previous article, How To Build a Modern Data Pipeline, we provided a guide on how to build a solid data pipeline that solves typical problems that analytics engineers face. On the other hand, this new article describes more in-depth integration with dbt because as we wrote in the article GoodData and dbt Metrics, we think that dbt metrics are good for simple use cases but for advanced analytics, you need a more solid tool like GoodData.
Despite the fact that our solution is tightly coupled with GoodData, we want to provide a general guide on how to integrate with dbt! Let’s start 🚀.
First thing first — why would you want to integrate with dbt? Before you start to write your own code, it is a good approach to do research of existing dbt plugins first. It is a known fact that the dbt has a very strong community with a lot of data professionals. If your use case is not very exotic or proprietary to your solution, I would bet that there already exists a similar plugin.
One example is worth a thousand words. Few months ago, we were creating our first prototype with dbt and jumped into a problem with referential integrity constraints. We had basically two options:
- Write a custom code to solve the problem.
- Find a plugin that would solve the problem.
Fortunately, we found a plugin dbt Constraints Package and then the solution was quite simple:
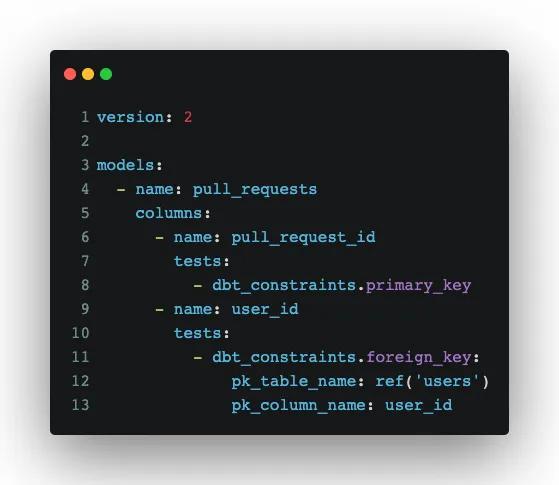
Lesson learned: Search for an existing solution first, before writing any code. If you still want to integrate dbt, let’s move to the next section.
Implementation: How To Integrate With dbt?
In the following sections, we cover the most important aspects of integration with dbt. If you want to explore the whole implementation, check out the repository.
Setup
Before we start writing custom code, we need to do some setup. First important step is to create a profile file:
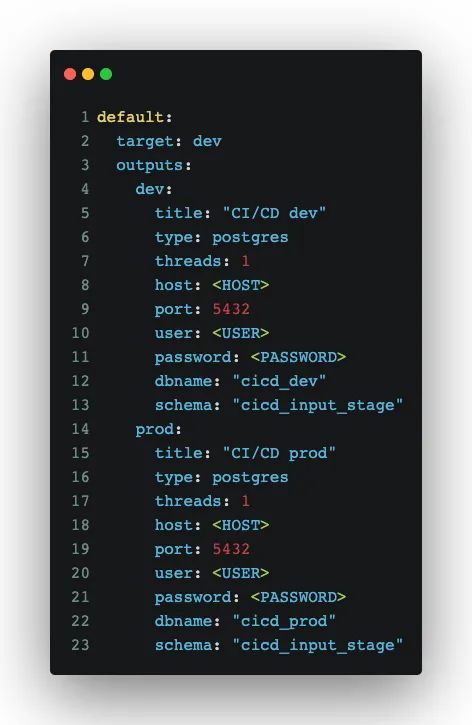
It is basically a configuration file with the database connection details. Interesting thing here is the partition between dev and prod. If you explore the repository, you will find that there is a CI/CD pipeline (described in How To Build a Modern Data Pipeline). The dev and prod environments make sure that every stage in the pipeline is executed with the right database.
The next step is to create a standard python package. It allows us to run the proprietary code within the dbt environment.
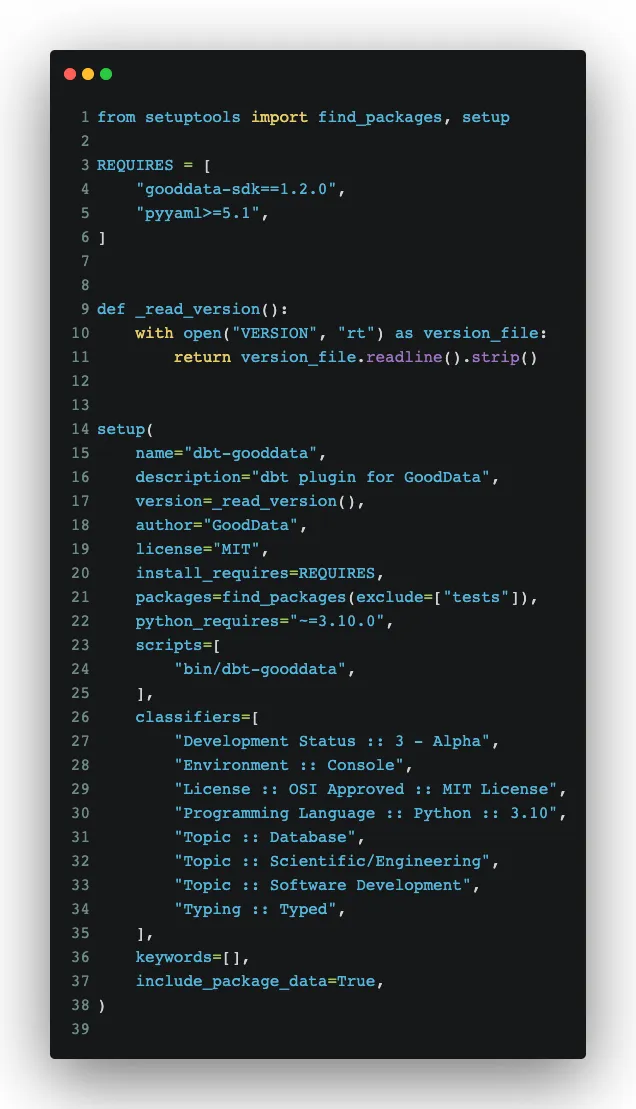
The whole dbt-gooddata package is in GitLab. Within the package, we can then run commands like:
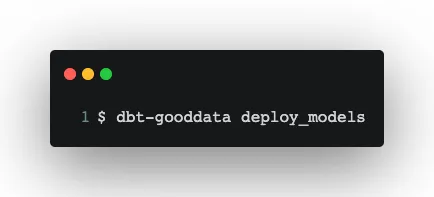
Transformation
Transformation was crucial for our use case. The output of dbt are materialized tables in the so-called output stage schema. The output stage schema is the point where GoodData connects but in order to successfully start to create analytics (metrics, reports, dashboards), we need to do a few things first, like connect to data source (output stage schema), or - what is the most interesting part — convert dbt metrics to GoodData metrics.
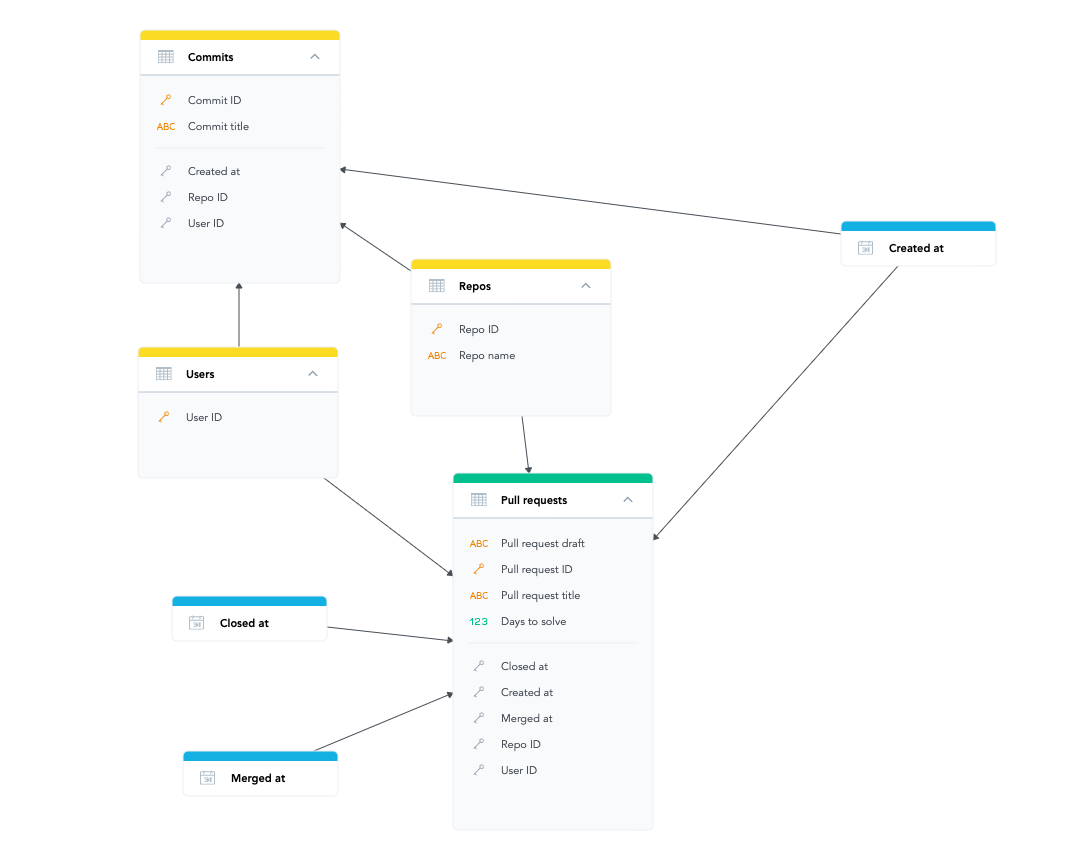
Let’s start with the basics. In GoodData, we have a concept called the Physical Data Model (PDM) that describes the tables of your database and represents how the actual data is organized and stored in the database. Based on the PDM, we also create a Logical Data Model (LDM) which is an abstract view of your data in GoodData. The LDM is a set of logical objects and their relationships that represent the data objects and their relationships in your database through the PDM.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product toursIf we use more simple words which are common in our industry — PDM is tightly coupled with a database, LDM is tightly coupled with analytics (GoodData). Almost everything you do in GoodData (metrics, reports) is based on the LDM. Why do we use the LDM concept? Imagine you change something in your database, for example, the name of a column. If GoodData did not have the additional LDM layer, you would need to change the column name in every place (every metric and every report, etc.). With LDM, you only change one property of the LDM, and the changes are automatically propagated throughout your analytics. There are other benefits too, but we will not cover them here — you can read about them in the documentation.
We covered a little theory, let’s check the more interesting part. How do we create PDM, LDM, Metrics, etc. from dbt generated output stage schemas? First of all, a schema description is the ultimate source of truth for us:
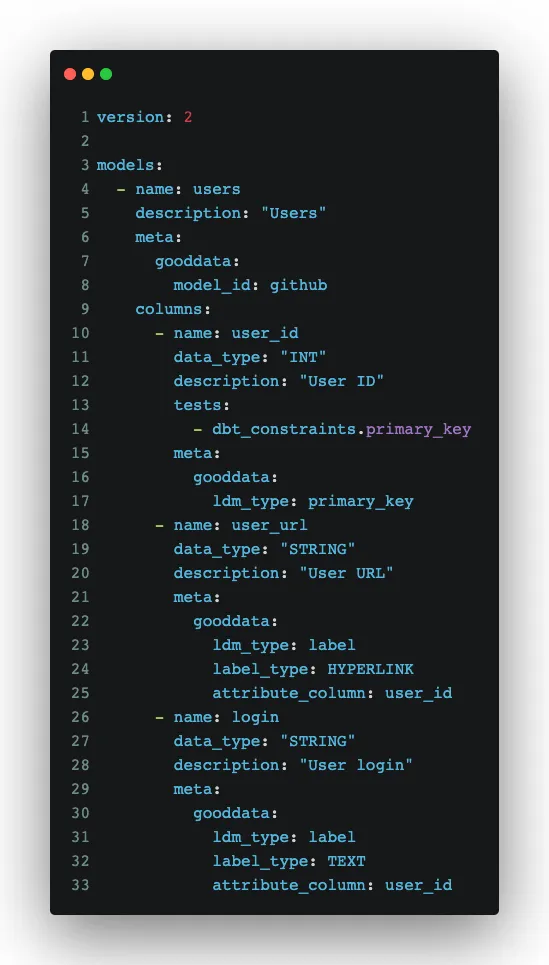
You can see that we use dbt standard things like date_type but we also introduced metadata that helps us with converting things from dbt to GoodData. For the metadata, we created data classes that guide us in application code:
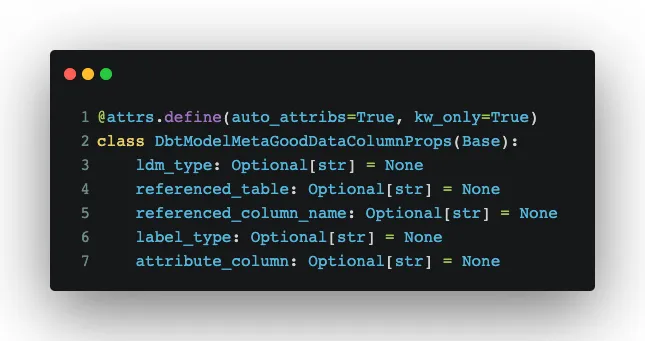
The data classes can be used in methods where we create LDM objects (for example, date datasets):
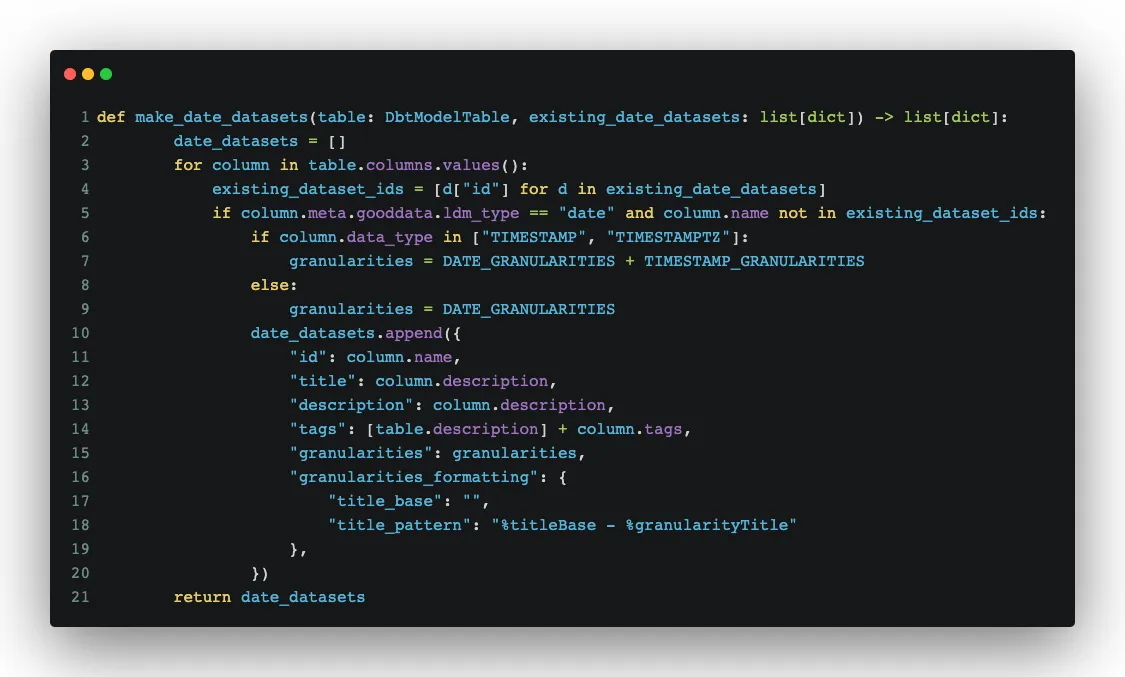
You can see that we work with metadata which helps us to convert things correctly. We use the result from the method make_date_datasets, together with other results, to create a LDM in GoodData through its API, or more precisely with the help of GoodData Python SDK:
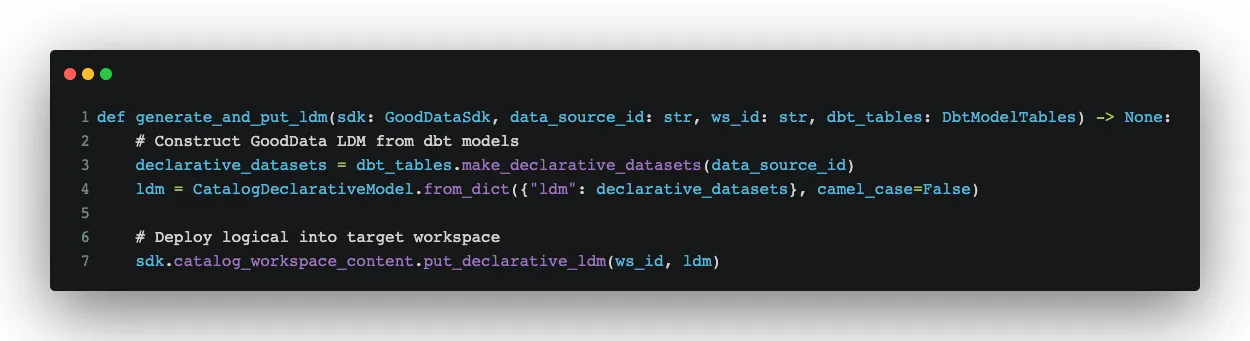
For those who would like to also explore how we convert dbt metrics to GoodData metrics, you can check the whole implementation.
Big Picture
We understand that the previous chapter can be overwhelming. Before the demonstration, let’s just use one image to show how it works for better understanding.
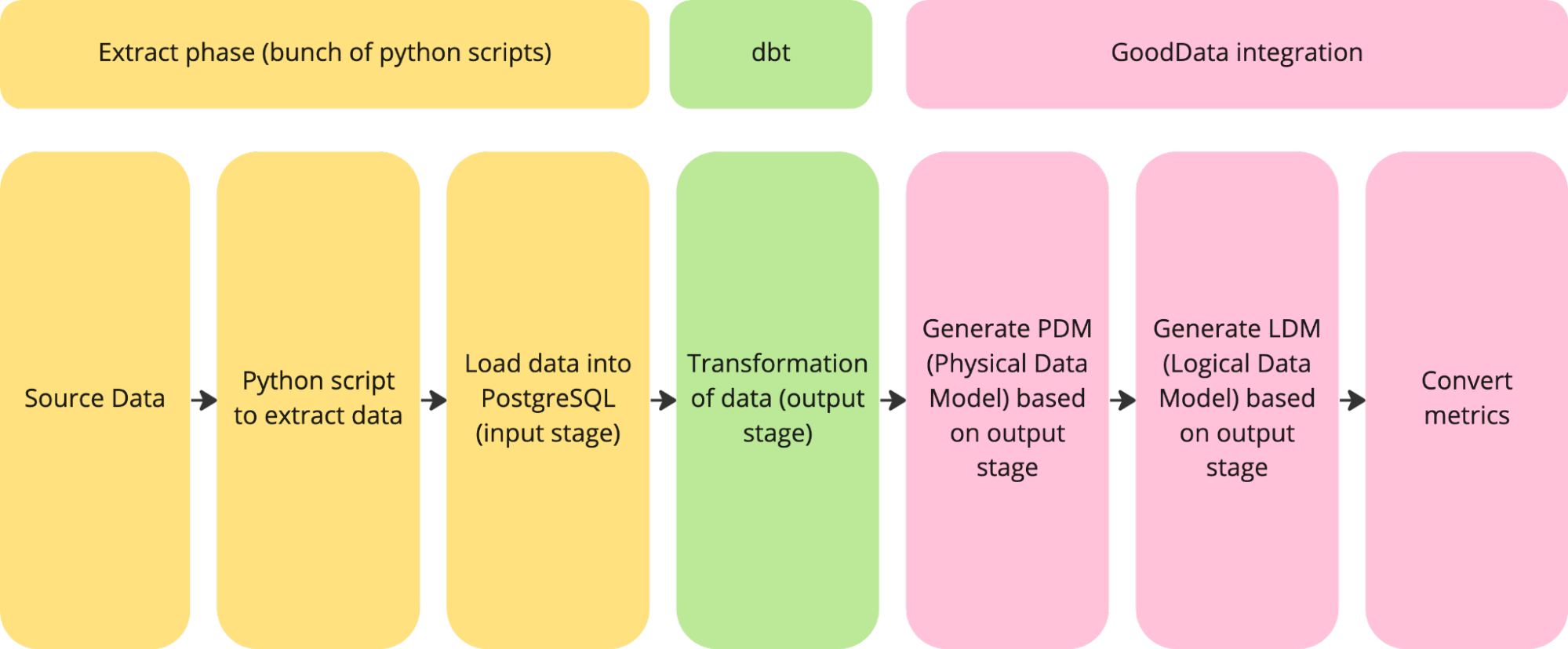
Demonstration: Generate Analytics From dbt
For the demonstration, we skip the extract part and start with transformation, which means that we need to run dbt:
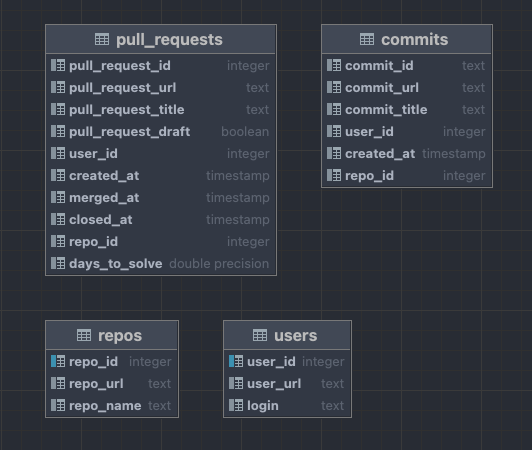
The result is output stage schema with the following structure:
Now, we need to get this output to GoodData to start analyzing data. Normally, you would need to do a few manual steps either in the UI or using API / GoodData Python SDK. Thanks to integration described in the implementation section, only one command needs to be run:
Here are the logs from the successful run:
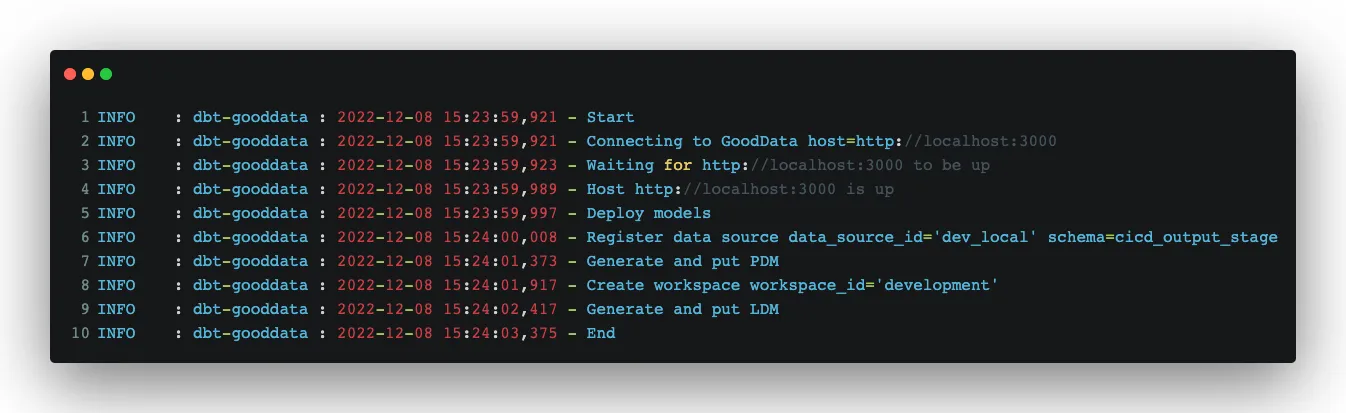
The final result is a successfully created Logical Data Model (LDM) in GoodData:
The very last step is to deploy dbt metrics to GoodData metrics. The command is similar to the previous one:
Here are the logs from the successful run:
Now, we can check how the dbt metric was converted to a GoodData metric:
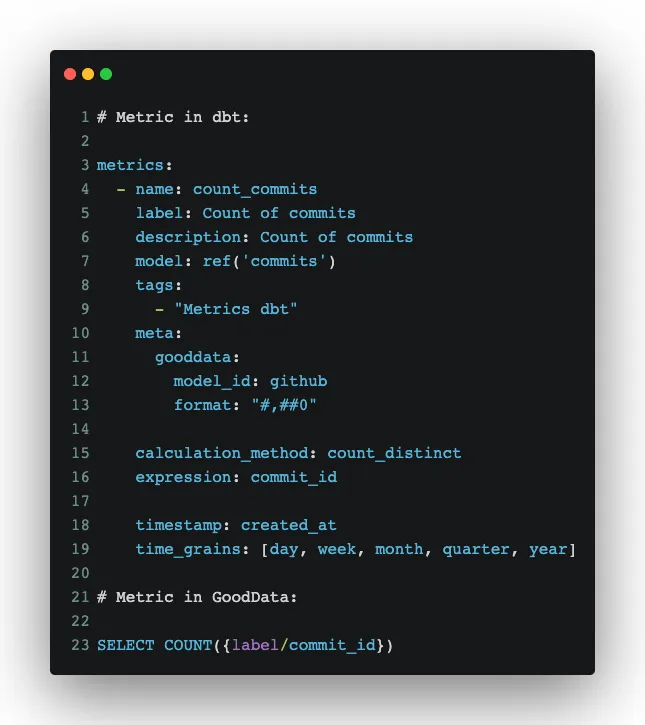
The most important thing is that you can now use the generated dbt metrics and build more complex metrics in GoodData. You can then build reports and dashboards and, once you are happy with the result, you can store the whole declarative analytics using one command and version in git:
For those of you who like automation, you can take inspiration from our article where we describe how to automate data analytics using CI/CD.
What Next?
The article describes our approach to integration with dbt. It is our very first prototype and in order to productize it, we would need to finalize a few things and then publish the integration as a stand alone plugin. We hope that the article can serve as an inspiration for your company, if you decide to integrate with dbt. If you take another approach, we would love to hear that! Thanks for reading!
If you want to try it on your own, you can register for the GoodData trial and play with it on your own.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product tours

