From RAG to GraphRAG: Knowledge Graphs, Ontologies and Smarter AI
12 min read | Published

Modern AI chatbots often rely on Retrieval-Augmented Generation (RAG), a technique where the chatbot pulls in external data to ground its answers in real facts. If you’ve used a “Chat with your” tool, you’ve seen RAG in action: the system finds relevant snippets from a document and feeds them into a Large Language Model (LLM) so it can answer your question with accurate information.
RAG has greatly improved the factual accuracy of LLM answers. However, traditional RAG systems mostly treat knowledge as disconnected text passages. The LLM is given a handful of relevant paragraphs and left to piece them together during its response. This works for simple questions, but it struggles with complex queries that require connecting the dots across multiple sources.
This article will demystify two concepts that can take chatbots to the next level, namely, ontologies and knowledge graphs, and show how they combine with RAG to form a GraphRAG (Graph-based Retrieval-Augmented Generation). We’ll explain what they mean and why they matter in simple terms.
Why does this matter, you might ask? Because GraphRAG promises to make chatbot answers more accurate, context-aware, and insightful than what you get with a traditional RAG. Businesses exploring AI solutions value these qualities — an AI that can truly understand context, avoid mistakes, and reason through complex questions can be a game-changer. (Although this needs a perfect implementation, which often is not the case in practice.)
By combining unstructured text with a structured knowledge graph, GraphRAG systems can provide answers that feel far more informed. Bridging knowledge graphs with LLMs is a key step toward AI that doesn’t just retrieve information, but actually understands it.
What is RAG?
Retrieval-Augmented Generation, or RAG, is a technique for enhancing language model responses by grounding them in external knowledge. Instead of replying based solely on what’s in its model memory, which might be outdated or incomplete, a RAG-based system will fetch relevant information from an outside source (e.g., documents, databases and the web) and feed that into the model to help formulate the answer.
In simple terms, RAG = LLM + Search Engine: the model first retrieves supporting data, augments its understanding of the topic and then generates a response using both its built-in knowledge and the retrieved info.
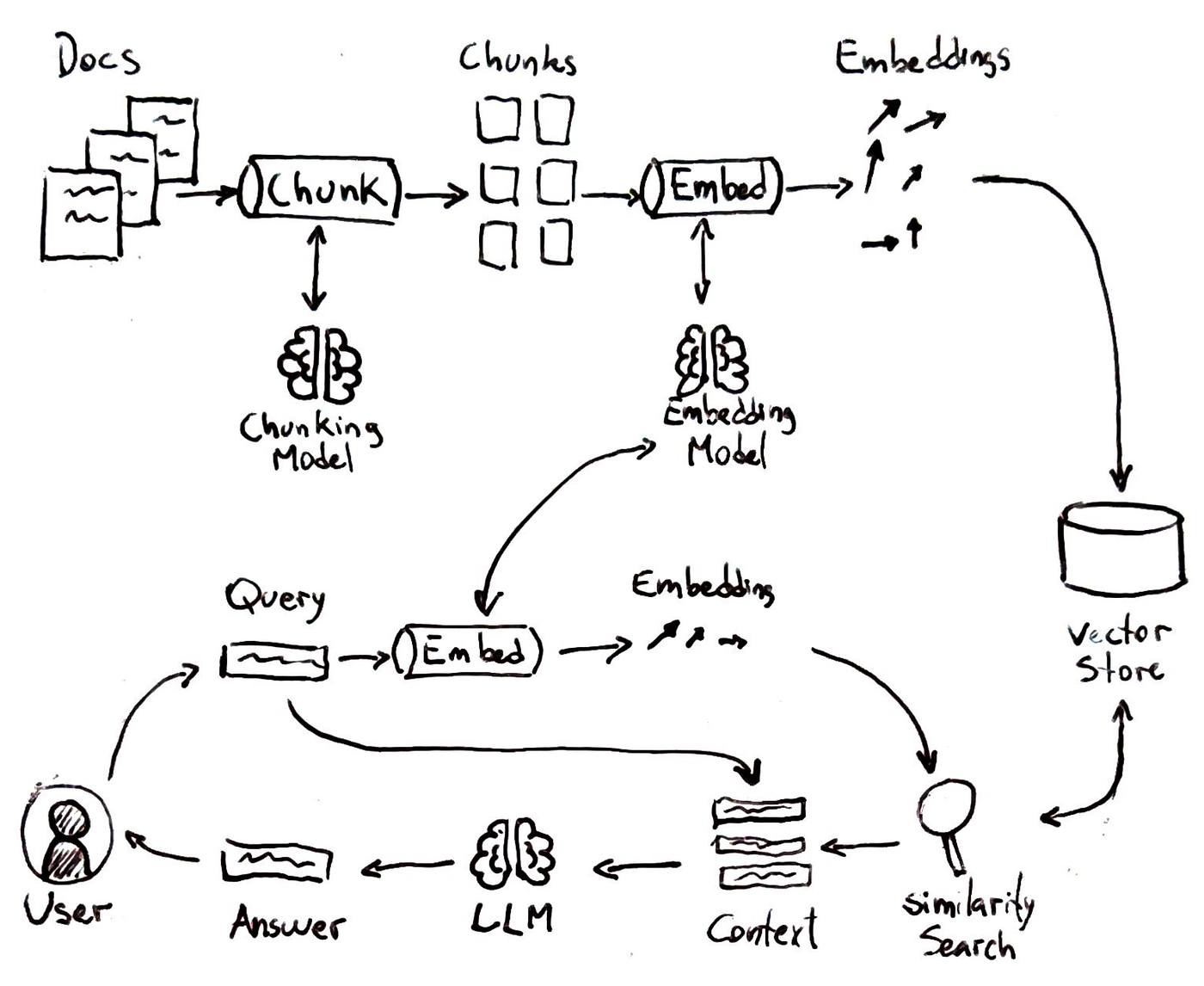
As shown in the figure above the typical RAG pipeline involves a few steps that mirror a smart lookup process:
Indexing Knowledge:
First, the system breaks the knowledge source (say a collection of documents) into chunks of text and creates vector embeddings for each chunk. These embeddings are numerical representations of the text meaning. All these vectors are stored in a vector database or index.
Query Embedding:
When a user asks a question, the query is also converted into a vector embedding using the same technique.
Similarity Search:
The system compares the query vector to all the stored vectors to find which text chunks are most “similar” or relevant to the question.
Generation with Context:
Finally, the language model is given the user’s question plus the retrieved snippets as context. It then generates an answer that incorporates the provided information.
RAG has been a big step forward for making LLMs useful in real-world scenarios. It’s how tools like Bing Chat or various document QA bots can provide current, specific answers with references. By grounding answers in retrieved text, RAG reduces hallucinations (the model can be pointed to the facts) and allows access to information beyond the AI’s training cutoff date. However, traditional RAG also has some well-known limitations:
- It treats the retrieved documents essentially as separate, unstructured blobs. If an answer requires synthesising info across multiple documents or understanding relationships, the model has to do that heavy lifting itself during generation.
- RAG retrieval is usually based on semantic similarity. It finds relevant passages but doesn’t inherently understand the meaning of the content or how one fact might relate to another.
- There is no built-in mechanism for reasoning or enforcing consistency across the retrieved data; the LLM just gets a dump of text and tries its best to weave it together.
In practice, for straightforward factual queries, e.g., “When was this company founded?”, traditional RAG is great. For more complex questions, e.g., “Compare the trends in Q1 sales and Q1 marketing spend and identify any correlations.”, traditional RAG might falter. It could return one chunk about sales, another about marketing, but leave the logical integration to the LLM, which may or may not succeed coherently.
These limitations point to an opportunity. What if, instead of giving the AI system just a pile of documents, we also gave it a knowledge graph (i.e. a network of entities and their relationships) as a scaffold for reasoning? If RAG retrieval could return not just text based on similarity search, but a set of interconnected facts, the AI system could follow those connections to produce a more insightful answer.
GraphRAG is about integrating this graph-based knowledge into the RAG pipeline. By doing so, we aim to overcome the multi-source, ambiguity, and reasoning issues highlighted above.
Before we get into how GraphRAG works, though, let’s clarify what we mean by knowledge graphs and ontologies — the building blocks of this approach.
Knowledge Graphs
A knowledge graph is a networked representation of real-world knowledge, where each node represents an entity and each edge represents a relationship between entities.
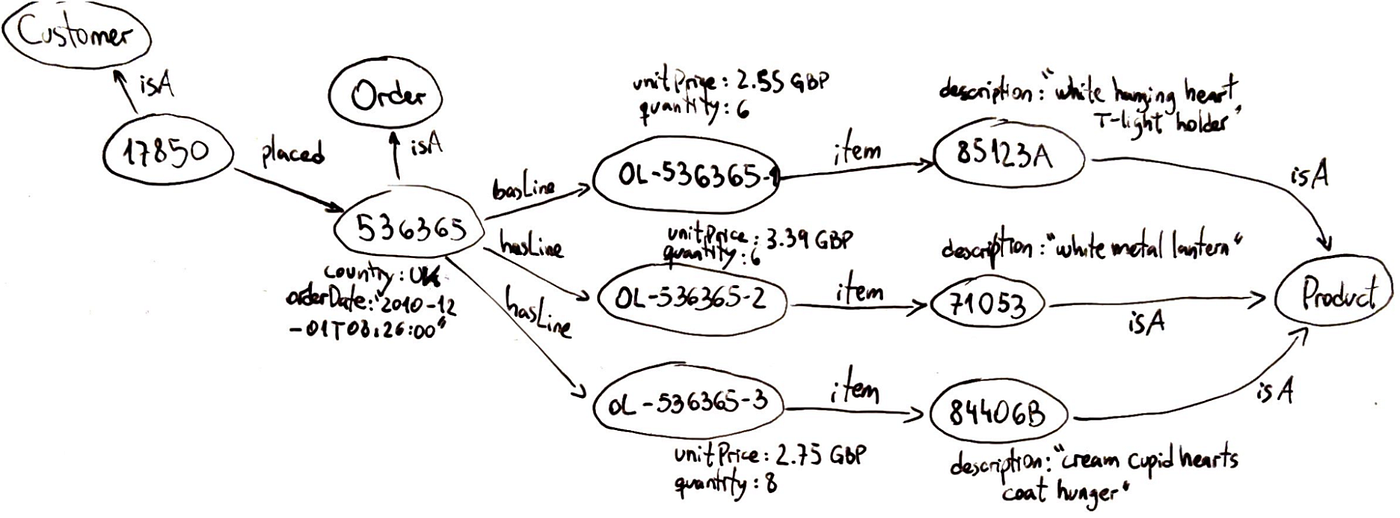
In the figure above, we see a graphical representation of what a knowledge graph looks like. It structures data as a graph, not as tables or isolated documents. This means information is stored in a way that inherently captures connections. Some key traits:
- They are flexible: You can add a new type of relationship or a new property to an entity without upending the whole system. Graphs can easily evolve to accommodate new knowledge.
- They are semantic: Each edge has meaning, which makes it possible to traverse the graph and retrieve meaningful chains of reasoning. The graph can represent context along with content.
- They naturally support multi-hop queries: If you want to find how two entities are connected, a graph database can traverse neighbors, then neighbors-of-neighbors, and so on.
- Knowledge graphs are usually stored in specialised graph databases or triplestores. These systems are optimised for storing nodes and edges and running graph queries.
The structure of knowledge graphs is a boon for AI systems, especially in the RAG context. Because facts are linked, an LLM can get a web of related information rather than isolated snippets. This means:
- AI systems can better disambiguate context. For example, if a question mentions “Jaguar,” the graph can clarify whether it refers to the car or the animal through relationships, providing context that text alone often lacks.
- An AI system can use “joins” or traversals to collect related facts. Instead of separate passages, a graph query can provide a connected subgraph of all relevant information, offering the model a pre-connected puzzle rather than individual pieces.
- Knowledge graphs ensure consistency. For example, if a graph knows Product X has Part A and Part B, it can reliably list only those parts, unlike text models that might hallucinate or miss information. The structured nature of graphs allows complete and correct aggregation of facts.
- Graphs offer explainability by tracing the nodes and edges used to derive an answer, allowing for a clear chain of reasoning and increased trust through cited facts.
To sum up, a knowledge graph injects meaning into the AI’s context. Rather than treating your data as a bag of words, it treats it as a network of knowledge. This is exactly what we want for an AI system tasked with answering complex questions: a rich, connected context it can navigate, instead of a heap of documents it has to brute-force parse every time.
Now that we know what knowledge graphs are, and how they can benefit AI systems, let’s see what ontologies are and how they may help to build better knowledge graphs.
Ontologies
In the context of knowledge systems, an ontology is a formal specification of knowledge for a particular domain. It defines the entities (or concepts) that exist in the domain and the relationships between those entities.
Press enter or click to view image in full size
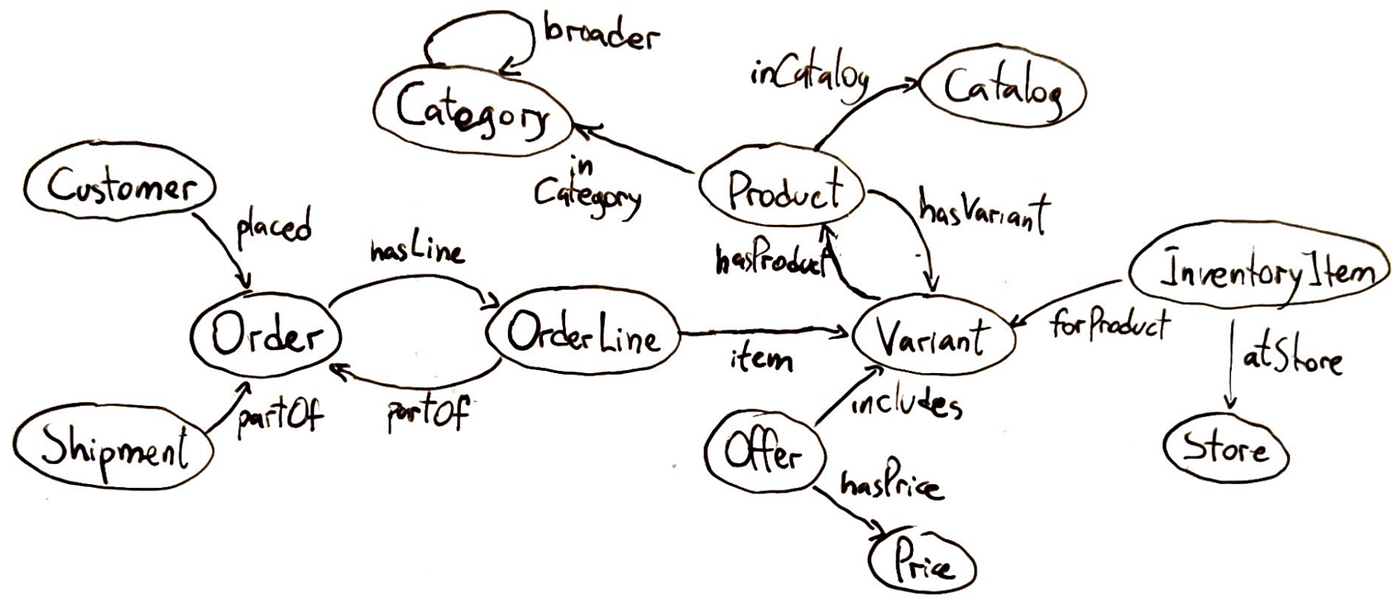
Ontologies often organise concepts into hierarchies or taxonomies. But can also include logical constraints or rules: for example, one could declare “Every Order must have at least one Product item.”
Why ontologies matter? You may ask. Well, an ontology provides a shared understanding of a domain, which is incredibly useful when integrating data from multiple sources or when building AI systems that need to reason about the domain. By defining a common set of entity types and relationships, an ontology ensures that different teams or systems refer to things consistently. For example, if one dataset calls a person a “Client” and another calls them “Customer,” mapping both to the same ontology class (say Customer as a subclass of Person) lets you merge that data seamlessly.
In the context of AI and GraphRAG, an ontology is the blueprint for the knowledge graph — it dictates what kinds of nodes and links your graph will have. This is crucial for complex reasoning. If your chatbot knows that “Amazon” in the context of your application is a Company (not a river) and that Company is defined in your ontology (with attributes like headquarters, CEO, etc., and relationships like hasSubsidiary), it can ground its answers much more precisely.
Now that we know about knowledge graphs and ontologies, let’s see how we put it all together in a RAG-alike pipeline.
GraphRAG
GraphRAG is an evolution of the traditional RAG approach that explicitly incorporates a knowledge graph into the retrieval process. In GraphRAG, when a user asks a question, the system doesn’t just do a vector similarity search over text; it also queries the knowledge graph for relevant entities and relationships.
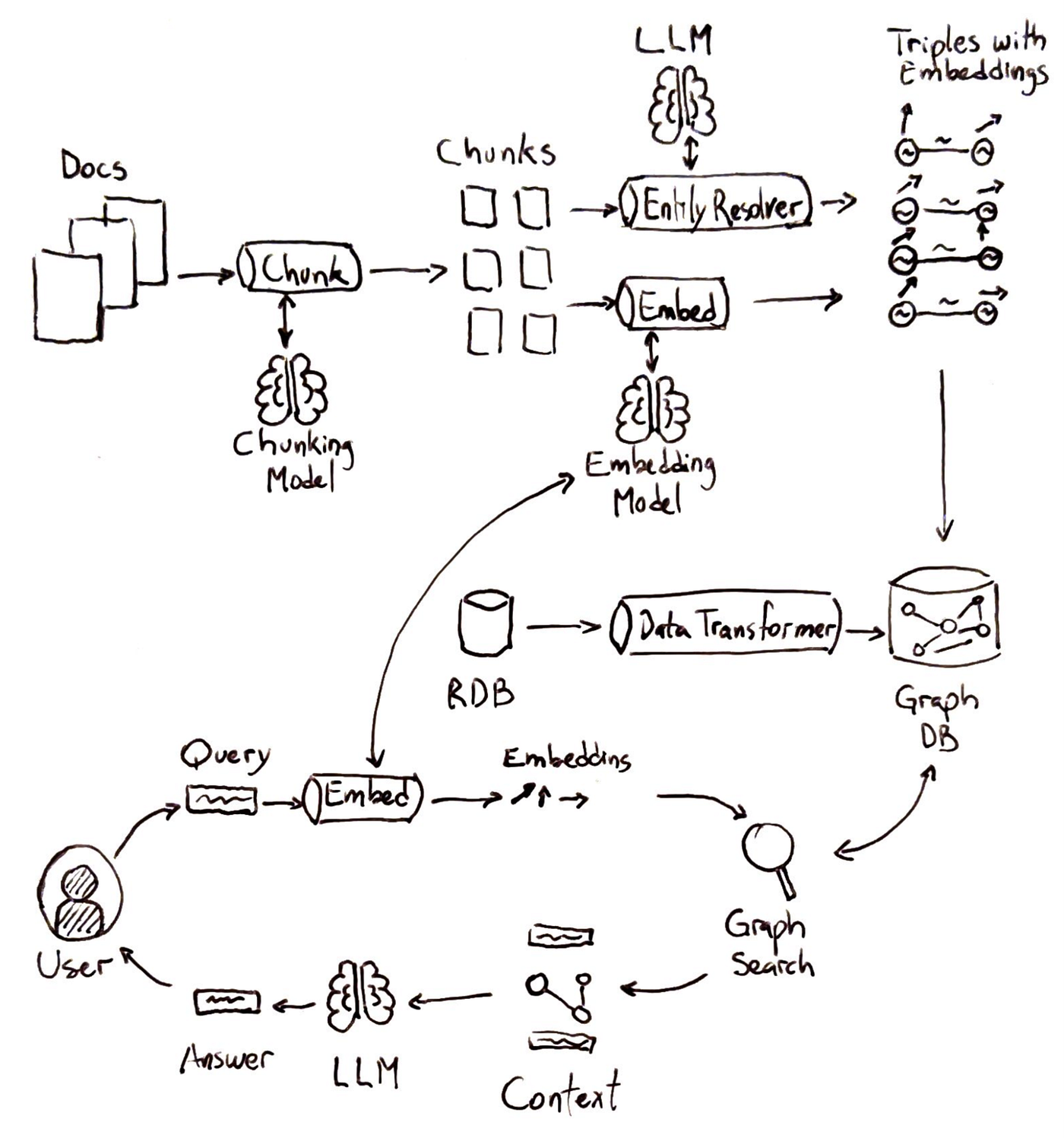
Let’s walk through a typical GraphRAG pipeline at a high level:
Indexing knowledge:
Both structured data (e.g., databases, CSV files) and unstructured data (e.g., documents) are taken as input. Structured data goes through data transformation, converting table rows to triples. Unstructured data is broken down into manageable text chunks. Entities and relationships are extracted from these chunks and simultaneously embeddings are calculated to create triples with embeddings.
Question Analysis and Embedding:
The user’s query is analyzed to identify key terms or entities. These elements are embedded with the same embedding model used for indexing.
Graph Search:
The system queries the knowledge graph for any nodes related to those key terms. Instead of retrieving only semantically similar items, the system also leverages relationships.
Generation with Graph Context:
A generative model uses the user’s query and the retrieved graph-enriched context to produce an answer.
Under the hood, GraphRAG can use various strategies to integrate the graph query. The system might first do a semantic search for top-K text chunks as usual, then traverse the graph neighborhood of those chunks to gather additional context, before generating the answer. This ensures that if relevant info is spread across documents, the graph will help pull in the connecting pieces. In practice, GraphRAG might involve extra steps like entity disambiguation (to make sure the “Apple” in the question is linked to the right node, either Company or Fruit) and graph traversal algorithms to expand the context. But the high-level picture is as described: search + graph lookup instead of search alone.
Overall, for non-technical readers, you can think of GraphRAG as giving the AI a “brain-like” knowledge network in addition to the library of documents. Instead of reading each book (document) in isolation, the AI also has an encyclopedia of facts and how those facts relate. For technical readers, you might imagine an architecture where we have both a vector index and a graph database working in tandem — one retrieving raw passages, the other retrieving structured facts, both feeding into the LLM’s context window.
Building a Knowledge Graph for RAG: Approaches
There are two broad ways to build the knowledge graph that powers a GraphRAG system: a Top-Down approach or a Bottom-Up approach. They’re not mutually exclusive (often you might use a bit of both), but it’s helpful to distinguish them.
Approach 1: Top-Down (Ontology First)
The top-down approach to ontology begins by defining the domain’s ontology before adding data. This involves domain experts or industry standards to establish classes, relationships, and rules. This schema, loaded into a graph database as empty scaffolding, guides data extraction and organization, acting as a blueprint.
Once the ontology (schema) is in place, the next step is to instantiate it with real data. There are a few sub-approaches here:
Using Structured Sources:
If you have existing structured databases or CSV files, you map those to the ontology. This can sometimes be done via automated ETL tools that convert SQL tables to graph data if the mapping is straightforward.
Extracting from Text via Ontology:
For unstructured data (like documents, PDFs, etc.), you would use NLP techniques but guided by the ontology. This often involves writing extraction rules or using an LLM with prompts that reference the ontology’s terms.
Manual or Semi-Manual Curation:
In critical domains, a human might verify each extracted triple or manually input some data into the graph, especially if it’s a one-time setup of key knowledge. For example, a company might manually input its org chart or product hierarchy into the graph according to the ontology, because that data is relatively static and very important.
The key is that with a top-down approach, the ontology acts as a guide at every step. It tells your extraction algorithms what to look for and ensures the data coming in fits a coherent model.
One big advantage of using a formal ontology is that you can leverage reasoners and validators to keep the knowledge graph consistent. Ontology reasoners can automatically infer new facts or check for logical inconsistencies, while tools like SHACL enforce data shape rules (similar to richer database schemas). These checks prevent contradictory facts and enrich the graph by automatically deriving relationships. In GraphRAG, this means answers can be found even if multi-hop connections aren’t explicit, as the ontology helps derive them.
Approach 2: Bottom-Up (Data First)
The bottom-up approach seeks to generate knowledge graphs directly from data, without relying on a predefined schema. Advances in NLP and LLMs enable the extraction of structured triples from unstructured text, which can then be ingested into a graph database where entities form nodes and relationships form edges.
Under the hood, bottom-up extraction can combine classical NLP and modern LLMs:
Named Entity Recognition (NER):
Identify names of people, organizations, places, etc., in text.
Relation Extraction (RE):
Identify if any of those entities have a relationship mentioned.
Coreference Resolution:
Figure out the referent of a pronoun in a passage, so the triple can use the full name.
There are libraries like spaCy or Flair for the traditional approach, and newer libraries that integrate LLM calls for IE (Information Extraction). Also, techniques like ChatGPT plugins or LangChain agents can be set up to populate a graph: the agent could iteratively read documents and call a “graph insert” tool as it finds facts. Another interesting strategy is using LLMs to suggest the schema by reading a sample of documents (this edges towards ontology generation, but bottom-up).
A big caution with bottom-up extraction is that LLMs can be imperfect or even “creative” in what they output. They might hallucinate a relationship that wasn’t actually stated, or they might mis-label an entity. Therefore, an important step is validation:
- Cross-check critical facts against the source text.
- Use multiple passes: e.g., first pass for entities, second pass just to verify and fill relations.
- Human spot-checking: Have humans review a sample of the extracted triples, especially those that are going to be high impact.
The process is typically iterative. You run the extraction, find errors or gaps, adjust your prompts or filters, and run again. Over time, this can dramatically refine the knowledge graph quality. The good news is that even with some errors, the knowledge graph can still be useful for many queries — and you can prioritize cleaning the parts of the graph that matter most for your use cases.
Finally, keep in mind that sending text for extraction exposes your data to the LLM/service, so you should ensure compliance with privacy and retention requirements.
Tools and Frameworks in the GraphRAG Ecosystem
Building a GraphRAG system might sound daunting, you need to manage a vector database, a graph database, run LLM extraction pipelines, etc. The good news is that the community is developing tools to make this easier. Let’s briefly mention some of the tools and frameworks that can help, and what role they play.
Graph Storage
First, you’ll need a place to store and query your knowledge graph. Traditional graph databases like Neo4j, Amazon Neptune, TigerGraph, or RDF triplestores (like GraphDB or Stardog) are common choices.
These databases are optimized for exactly the kind of operations we discussed:
- traversing relationships
- finding neighbors
- executing graph queries
In a GraphRAG setup, the retrieval pipeline can use such queries to fetch relevant subgraphs. Some vector databases (like Milvus or Elasticsearch with Graph plugin) are also starting to integrate graph-like querying, but generally, a specialized graph DB offers the richest capabilities. The important thing is that your graph store should allow efficient retrieval of both direct neighbors and multi-hop neighborhoods, since a complex question might require grabbing a whole network of facts.
Emerging Tools
New tools are emerging to combine graphs with LLMs:
- Cognee — An open-source “AI memory engine” that builds and uses knowledge graphs for LLMs. It acts as a semantic memory layer for agents or chatbots, turning unstructured data into structured graphs of concepts and relationships. LLMs can then query these graphs for precise answers. Cognee hides graph complexity: developers only need to provide data, and it produces a graph ready for queries. It integrates with graph databases and offers a pipeline for ingesting data, building graphs, and querying them with LLMs.
- Graphiti (by Zep AI) — A framework for AI agents needing real-time, evolving memory. Unlike many RAG systems with static data, Graphiti updates knowledge graphs incrementally as new information arrives. It stores both facts and their temporal context, using Neo4j for storage and offering an agent-facing API. Unlike earlier batch-based GraphRAG systems, Graphiti handles streams efficiently with incremental updates, making it suited for long-running agents that learn continuously. This ensures answers always reflect the latest data.
- Other frameworks — Tools like LlamaIndex and Haystack add graph modules without being graph-first. LlamaIndex can extract triplets from documents and support graph-based queries. Haystack experimented with integrating graph databases to extend question answering beyond vector search. Cloud providers are also adding graph features: AWS Bedrock Knowledge Bases supports GraphRAG with managed ingestion into Neptune, while Azure Cognitive Search integrates with graphs. The ecosystem is evolving quickly.
No Need to Reinvent the Wheel
The takeaway is that if you want to experiment with GraphRAG, you don’t have to build everything from scratch. You can:
- Use Cognee to handle knowledge extraction and graph construction from your text (instead of writing all the prompts and parsing logic yourself).
- Use Graphiti if you need a plug-and-play memory graph especially for an agent that has conversations or time-based data.
- Use LlamaIndex or others to get basic KG extraction capabilities with just a few lines of code.
- Rely on proven graph databases so you don’t have to worry about writing a custom graph traversal engine.
In summary, while GraphRAG is at the cutting edge, the surrounding ecosystem is rapidly growing. You can leverage these libraries and services to stand up a prototype quickly, then iteratively refine your knowledge graph and prompts.
Conclusion
Traditional RAG works well for simple fact lookups, but struggles when queries demand deeper reasoning, accuracy, or multi-step answers. This is where GraphRAG excels. By combining documents with a knowledge graph, it grounds responses in structured facts, reduces hallucinations, and supports multi-hop reasoning. Thus enabling AI to connect and synthesize information in ways standard RAG cannot.
Of course, this power comes with trade-offs. Building and maintaining a knowledge graph requires schema design, extraction, updates, and infrastructure overhead. For straightforward use cases, traditional RAG remains the simpler and more efficient choice. But when richer answers, consistency, or explainability matter, GraphRAG delivers clear benefits.
Looking ahead, knowledge-enhanced AI is evolving rapidly. Future platforms may generate graphs automatically from documents, with LLMs reasoning directly over them. For companies like GoodData, GraphRAG bridges AI with analytics, enabling insights that go beyond “what happened” to “why it happened.”
Ultimately, GraphRAG moves us closer to AI that doesn’t just retrieve facts, but truly understands and reasons about them, like a human analyst, but at scale and speed. While the journey involves complexity, the destination (more accurate, explainable, and insightful AI) is well worth the investment. The key lies in not just collecting facts, but connecting them.
To see more of GoodData's AI featureset, request a demo.


