Evaluation of AI Applications In Practice
6 min read | Published


In recent years, many companies have rushed to develop AI features or products, yet most initiatives fail to progress beyond the proof-of-concept stage.
The main reason behind the failure to productize these applications is often a lack of evaluation and proper data science. The so-called “vibe” development paradigm can only get you so far before things start to fall apart and you begin to feel like you are building something on top of a quicksand.
In this article, I describe how to address these problems by discussing the proper evaluation of applications that utilize LLMs and how to leverage this knowledge to produce reliable solutions.
Lifecycle Of AI Application Development
There is nothing wrong with writing custom prompts without any evaluation when starting a new product or feature. On the contrary, I would argue that it is a preferred approach when you need to create a proof-of-concept as quickly as possible. However, after a while, you will find that it is insufficient, especially when you begin to transition to the production phase. Without proper evaluation, you will end up going in circles from one regression to another.
Moreover, you do not have any data to support the reliability of your solution.Therefore, after the initial phase of prototyping your idea, you should move to implementing the evaluation of your AI application. With the evaluation in place, you can get confidence in how your solution performs and improve it iteratively without reintroducing bugs or undesired behavior.
Furthermore, you can move on to another step in AI app development and use prompt optimizers such as DSPy and discard manual prompt tuning completely. You can see this lifecycle visualized below:

Evaluation of AI Applications
Evaluating AI applications differs significantly from traditional software testing or data science validation. These systems, often referred to as Software 3.0, blend traditional software engineering with data science. As a result, the evaluation does not focus on the underlying LLM, nor does it resemble standard unit testing. Instead, it assesses the behavior of an application built on top of various AI models, such as LLMs, embedding models, and rerankers.
The primary objective is to evaluate the configuration of the complete AI system. This might include RAG pipelines (retrieval and reranking stages), prompt templates (e.g., structured instructions, few-shot examples, prompting strategies), and any surrounding pre-/post-processing logic. This article focuses specifically on the evaluation of the LLM components (i.e., prompt templates) of such applications. The evaluation of RAG pipelines falls under the domain of information retrieval and deserves a separate article.
To conduct a meaningful evaluation, three core elements are needed:
A
dataset
with ground truth outputs, if available,
Appropriate
evaluation metrics
that reflect desired behavior
An evaluation infrastructure to run and monitor the evaluation process.
Datasets
To evaluate an AI application, you need a dataset with expected outputs, also called ground truth. The hardest part is often getting the initial dataset. Fortunately, even a tiny dataset can help you meaningfully tune your application and check if it behaves as expected.
There are three main ways to obtain a dataset. First, you can manually write a few input-output pairs. This helps clarify exactly what you expect from the application, rather than relying on vague specifications. Second, if your company policy allows and the application is already running, you can use user interactions with positive feedback to extend the dataset. Lastly, you can use an LLM to generate synthetic examples from crafted prompts or existing dataset items, but always review these carefully before using them.
Evaluation Metrics
Choosing the right metrics is crucial when performing an evaluation to determine whether your AI application behaves as you expect. Metrics can assess the output on their own (e.g., politeness, toxicity, contextual relevance) or measure how closely it aligns with the expected result. Broadly, these evaluation metrics fall into three categories: analytical metrics (commonly used in traditional ML), deterministic assertions (akin to unit tests), and LLM-as-a-judge (a newer approach using LLM for evaluation).
A common mistake is to start with LLM-as-a-Judge and use it for every aspect of the evaluation. While the LLM-as-a-judge is selected for its ease of use, this approach comes with significant drawbacks. These include the cost and latency of calling the judge itself, as well as the uncertainty it introduces into the evaluation.
Therefore, it is recommended to use LLM-as-a-Judge always as a last resort when traditional approaches such as analytical metrics or deterministic assertions are not enough. It is beneficial to consider these metrics in a similar manner to unit, integration, and E2E tests, where E2E tests are akin to LLM-as-a-judge since they have the highest cost. Here is the view of these metric types visualized :
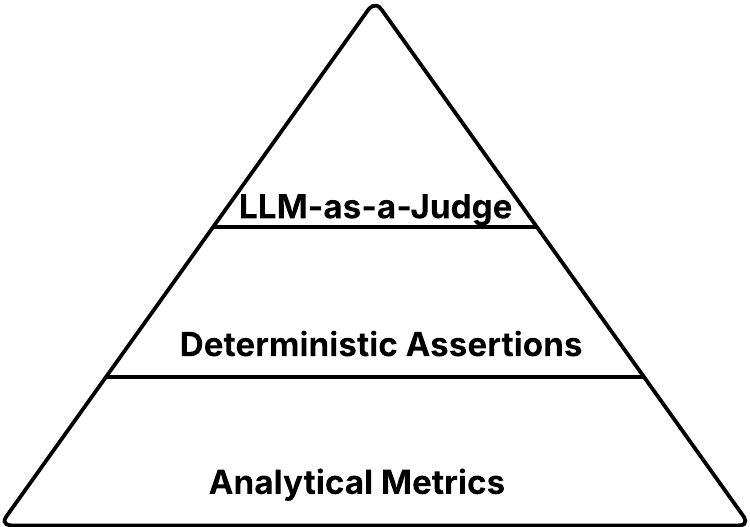
Analytical Metrics
Analytical metrics are quantitative functions that assign a numerical score to the output of the AI application. These metrics are present at the bottom of our pyramid since they are broadly applicable to all test cases with minimal implementation or real cost. Let’s describe these metrics, explain how to use them, and discuss their interpretation. Note that the selection of a metric always depends on the specific use case you are evaluating.
Let’s list commonly used analytical metrics:
Perplexity
Explanation:
Perplexity measures how well the model predicts the sequence of tokens. It is defined as the exponentiated average negative log-likelihood of a token sequence.
Interpretation:
The lower the perplexity, the more confident the LLM is in its prediction.
Use Case
: It is a good practice to track Perplexity every time you have access to the token output probabilities.
Cosine Similarity
Explanation:
Cosine similarity measures how similar two embedding vectors are. These vectors are produced by encoder models (e.g., BERT) trained to capture the semantic meaning of sentences. The similarity corresponds to the cosine of the angle between the vectors.
Interpretation:
The cosine similarity score can be challenging to interpret because it depends significantly on the underlying embedding models and the distribution of scores they produce.
Use Case:
Due to the difficulty of interpretation, I would not recommend relying on this measure when doing iterative development, but it can be leveraged in automatic prompt optimization frameworks.
NLP Metrics (BLUE, ROUGE, METEOR)
Explanation:
Traditional NLP metrics that compare differences between two texts use token-level overlaps, n-grams, or the number of edits to get the same text.
Interpretation:
The result of these metrics is usually normalized between zero and one, where one is the best possible score.
Use Case:
These types of metrics are ideal for relatively short texts with lower variability.
Other
- Apart from the aforementioned metrics, you can track a host of other aspects of the generation, such as the number of tokens, the number of reasoning tokens, latency, cost, etc.
Our Evaluation Infrastructure
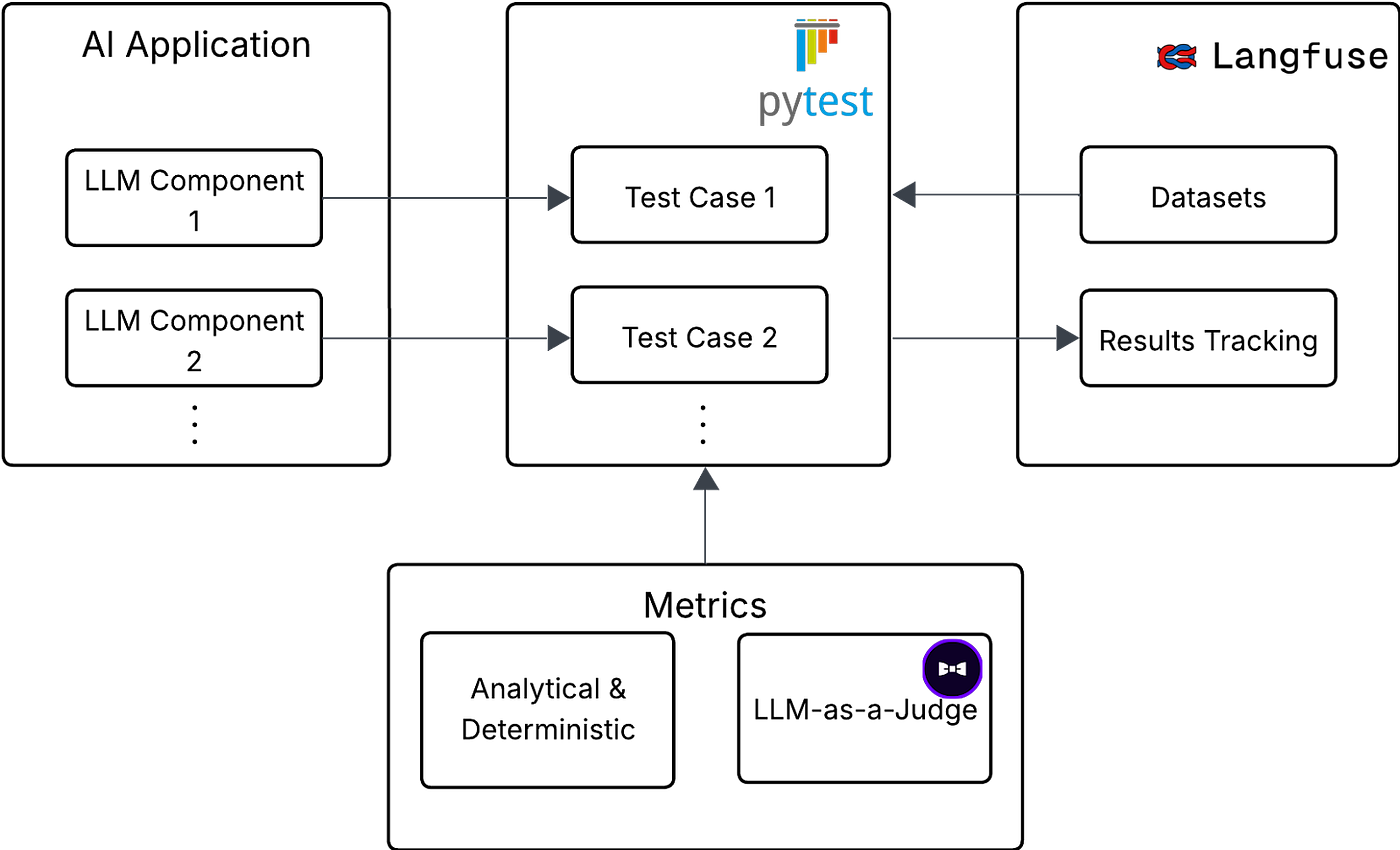
To achieve proper evaluation in the compound AI system with multiple components that depend on each other and take advantage of LLM, it is essential to have these LLM components encapsulated so they can be easily tested and evaluated.
This approach was inspired by the chapter “Design Your Evaluation Pipeline” from the book AI Engineering by Chip Huyen.
In our evaluation infrastructure, each LLM component has its own dataset and evaluation pipeline. You can think of the LLM component as an arbitrary machine learning model that is being evaluated. This separation of components is necessary in a complex application like ours, which focuses on an AI-assisted analytics use case, because evaluating such a system end-to-end can be extremely challenging.
To evaluate each of these components, we use the following tools:
Langfuse
- An LLM observability framework that is used primarily to track and log user interaction with an AI application
- Additionally, it supports dataset and experiment tracking, which we employ in our infrastructure.
Pytest
- It is a minimalistic framework for running unit tests
- We use it as our script runner when evaluating different LLM components
DeepEval
An LLM evaluation framework that implements evaluation metrics
We use it mainly for its
implementation
For each component, we have precisely one test. Each test is parametrized using the pytest_generate_tests function, so it runs for each item of the dataset for each element. The whole infrastructure setup with the use of these tools visualized:
The results of the evaluation of the specific LLM component are logged to the Langfuse, shown in the next image. As you can see, we are using G-Eval LLM-as-a-Judge. We are thresholding scores from the G-Eval to determine if the output is correct. On top of that, we are tracking the perplexity of the model. If perplexity values start to spike, it can be an indication that something might be wrong in the configuration of the LLM component.
Conclusion
Evaluation is essential for building reliable and production-ready AI applications. Compared to traditional unit testing or model evaluation, evaluating AI systems presents its unique challenges. The first step is always creating or gathering a dataset that matches your business goals and helps guide improvements. Then, selecting the right metrics is crucial to understanding how effectively your system performs. With these foundations in place, you can apply the ideas through a practical evaluation setup, as described in this article. I hope it helps you take the next step in evaluating your AI application.


