Can GoodData connect to…?
3 min read | Published


Hold that thought. The answer is yes.
Companies of all sorts need to analyze their data. We get that. A company's data comes from all over the place - CRMs, ERPs, SQL databases, and CSV files, and people from all sorts of business roles, doing all sorts of business stuff, are going to need an analytics platform that works for them. We get that, too.
That's actually why we have built the first entirely cloud-based business intelligence platform based on an analytical engine for real world complex data.
What kind of complex data?
Data describing multiple different entities, business processes, many-to-many relationships, you name it. Your users don’t need any data blending to run cross data source analytics. Just describe how the data relates to each other, how you want to measure the underlying processes, and get ready to go.
More importantly, we have developed a framework that allows us to add new data sources easily. Are you an early adopter of a startup nobody has yet heard about? No problem at all—just let us know.
How does it work?
Data downloaders running within the GoodData platform download the data from your sources into a staging area such as AWS S3. Once the data is downloaded, an integrator process is triggered that merges the downloaded data into your data warehousing tables (or creates the target tables if they don’t exist yet).
The data downloads and integrations are scheduled and managed through a data loading web console or programmatically via API.
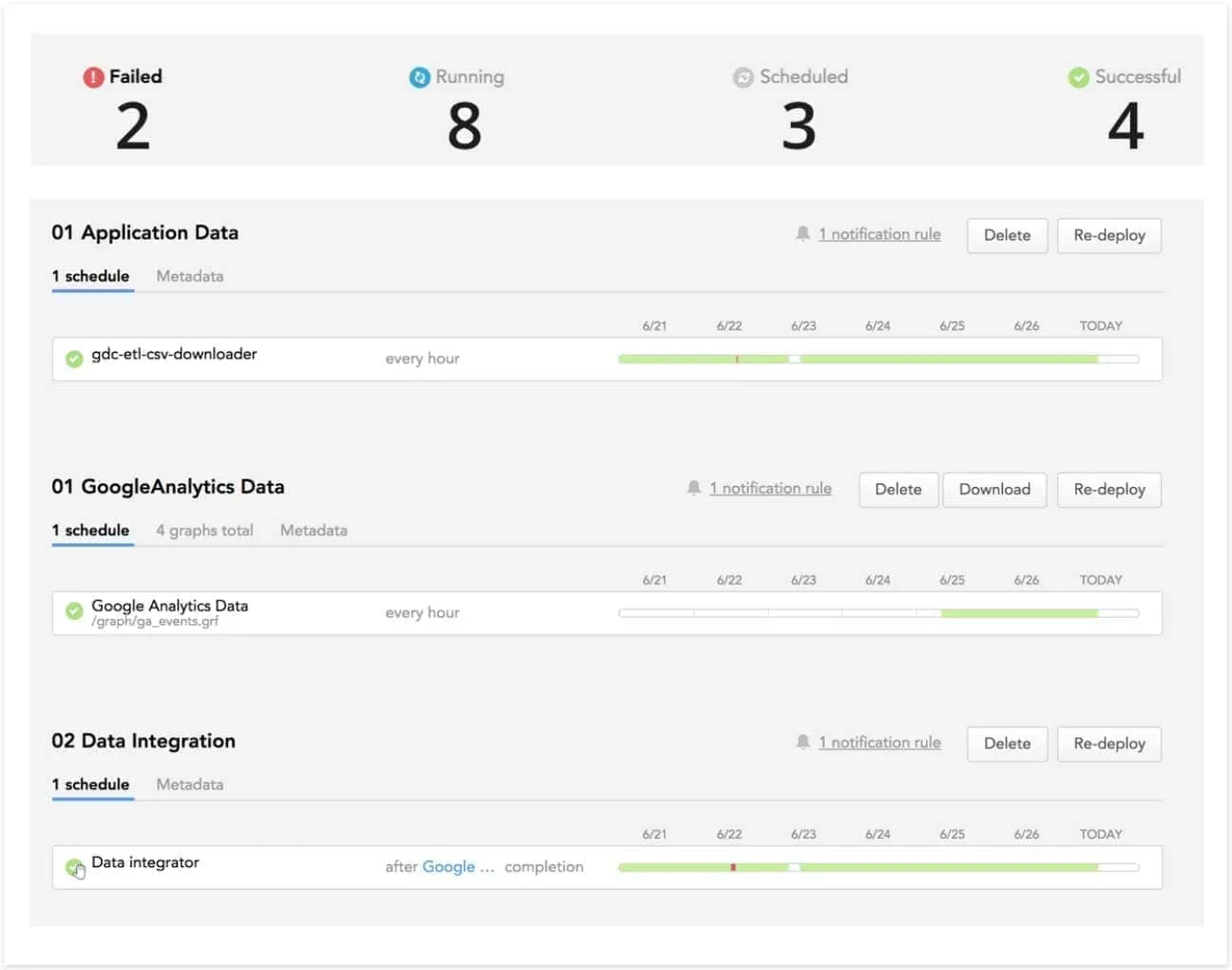
The framework behind the data downloaders and integrations has been designed with a focus on the following properties:
- Robust
- Smart and efficient
- Adaptable
- Consistent
- Developer friendly
- Open and modular
What does it all mean?
Robust: Things may go wrong at the data source. We comply with source-specific rate limits, we include careful auto-retry logic, and we don’t let a source system’s hiccup ruin the entire process.
What if something’s broken at the data warehouse level? No problem. Because of the separation between download and integration, the data keeps downloading and will be merged once the problem is fixed.
The history of all loads is kept in the archive area, including both data and metadata. For every download task, we know what was downloaded, when and from where. And if something goes wrong with your data warehouse, you can re-play all integration from the archive area.
Smart and efficient: Don’t download data you don’t need, take advantage of incremental loads. Don’t worry about the performance of data warehouse integration, it comes fine-tuned by our architects. Do you prefer more control? No problem. All advanced configuration options are described in our documentation.
Adaptable: When a new field is added to the source system, we detect it automatically—no reconfiguration or modification of target tables required.
Consistent: The status of all data sources is tracked in consistent metadata tables, and the retrieved data is enhanced with metadata columns holding information about source systems, last modification times, and so on.
Developer friendly: SQL is the lingua franca of data engineers. The data from the source systems manifest as relational entities, flexible flattening of non-relational structures included.
Open and modular: Support for new data sources can be added easily on demand. The downloaded data is accessible via SQL and JDBC interface. Full transparency, no blackbox.
Technology is constantly evolving; we see that evolution within our own platform and within our customers’ products. As such, we know that being able to support new technologies or new data sources as they’re made available helps us ensure that our customers can build the best products possible.
By working to improve our data source capabilities, we can support any data source that a customer may use. That flexibility helps our customers choose the technology that best suits their needs while still being able to harness the power and scalability of the GoodData platform.
Experience GoodData in Action
Discover how our platform brings data, analytics, and AI together — through interactive product walkthroughs.
Explore product tours


