A Simple Recipe for a Serverless AI Assistant


How can we apply AI to products we build? We’ve been asking this question here at GoodData and we’ve built numerous PoCs during the last year to find the answer. We’ve even held a hackathon with several AI-based projects in the lineup. In this article I’ll be sharing our family recipe for a simple AI assistant that you can make at home.
LLM (Large Language Model) is probably the most hyped technology at the moment, and for a good reason. Sometimes it feels like magic. But, really, its ingredients have been known for decades: text tokenization, text embedding and neural network. So why is it getting momentum only now?
Never before has a language model been trained on such a vast amount of data. What’s even more impressive to me is how accessible LLM has become to folks like you and me.
If you know how to make a REST API call - you can build an AI assistant.
No need to train your own model, no need to deploy it anywhere. It’s super easy to cook-up a PoC for your specific software product using the likes of OpenAI. All you need to follow along are some Front-end development skills and a little free time.
The main ingredient: LLM
The main ingredient is, of course, the LLM itself. The folks at OpenAI did a great job designing Chat Completion REST API. It’s simple, stateless, yet very powerful. You can use it with a framework, like LangChain, but the raw REST API is more than enough, especially if you want to go serverless.
A serverless chat app is very easy to build, but it’s more of a PoC tool. There are security implications in exposing your OpenAI Token in the browser environment, so at very least you’ll have to build an authenticating proxy if you want to use this in production.
Let’s have a closer look at the request to OpenAI Chat Completion API.
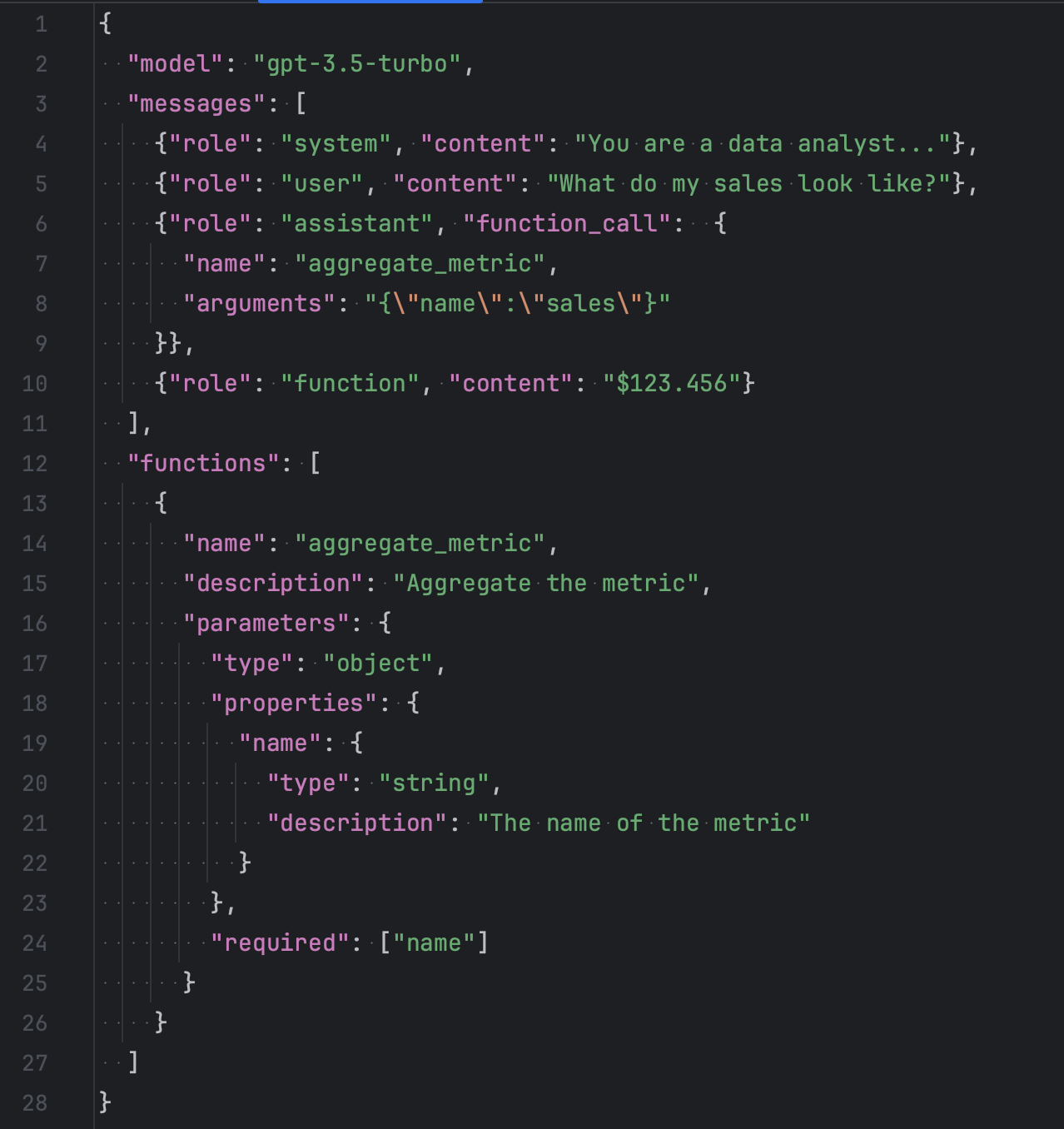
First we need to specify a model to be used for this request. gpt-3.5-turbo is a good default. If you need to work with a more complex text and you don’t care that much about speed and cost - try gpt-4 instead.
Next, we have the messages field holding the conversation history. And this is the first tool that you can use to make the assistant your own and not just a generic conversationalist. You can give the context to the conversation using a system message. For example, in my case I tell the chat about the data analytical workspace the user is currently logged into in GoodData, what kind of metrics and dimensions are available and what kind of questions the assistant should be able to answer.
Finally, the functions field holds the description of functions that LLM may ask us to run on the user's behalf. Think of it as a bridge between generic natural language capabilities of the LLM and your domain-specific logic. For example, in a data analytics solution we can define a “aggregate_metric” function that may be called if the user asks the chat about the value of some metric.
OpenAI recently introduced a new Assistant API that looks very promising. I’m not covering it here because it’s still in beta and we don’t really need all the features for the simplest cases described in here.
The recipe
The chat application is no more complex than any other frontend app. Here are the ingredients you’ll need:
- Redux store or other state machine to hold the conversation history.
- A store middleware that listens to new messages and communicates with OpenAI when necessary.
- Another middleware that listens to new messages and triggers a function execution when needed.
- A good measure of React/Angular/Vue (to taste) to build the UI.
Let’s see how it works.
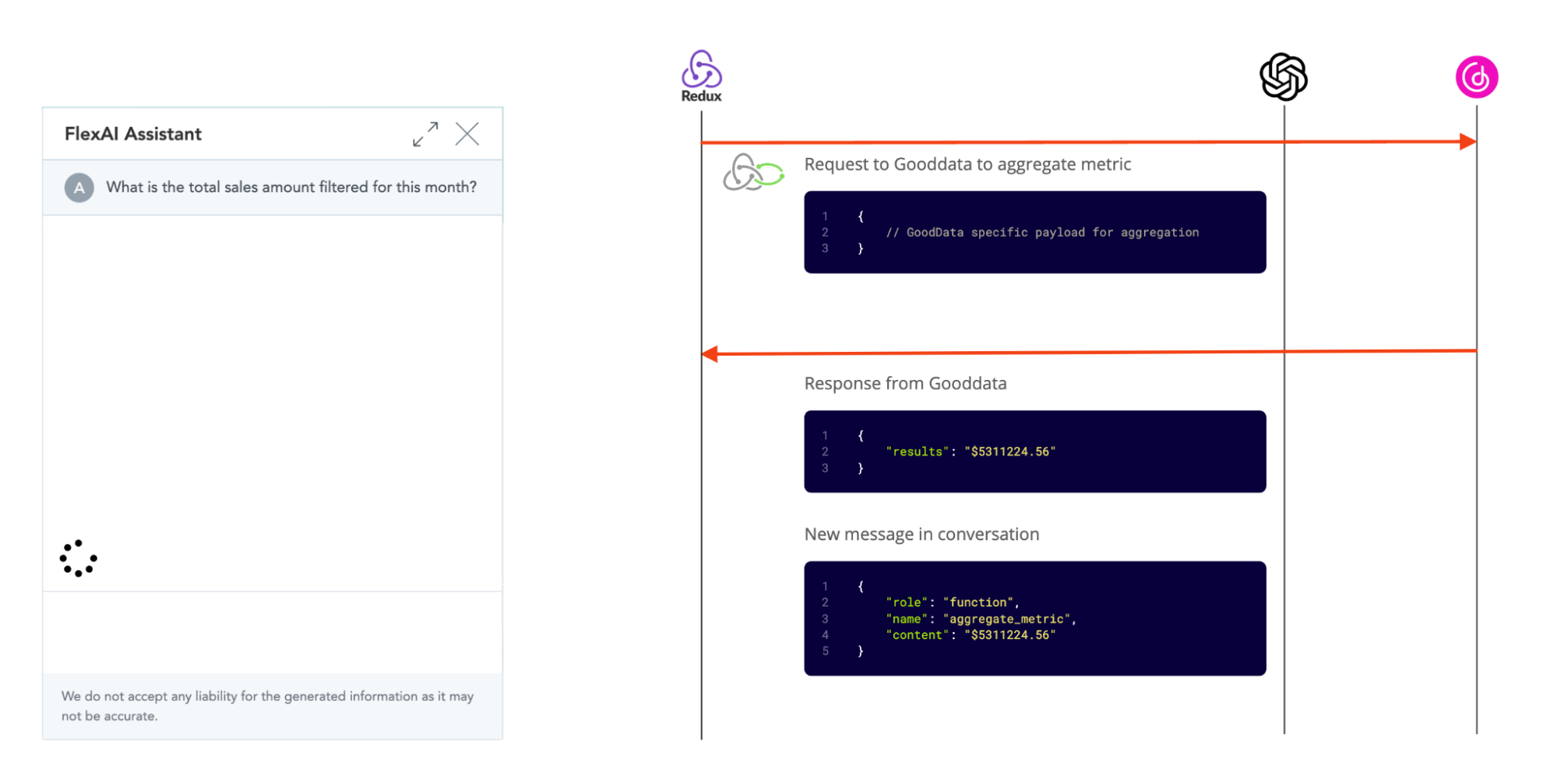
Step 1: Taking the order
It all starts with the user asking a question. A new message is added to the store and a middleware is triggered to send the whole messages stack to the OpenAI server.
Upon receiving the response from LLM we put it to the store as a new message.
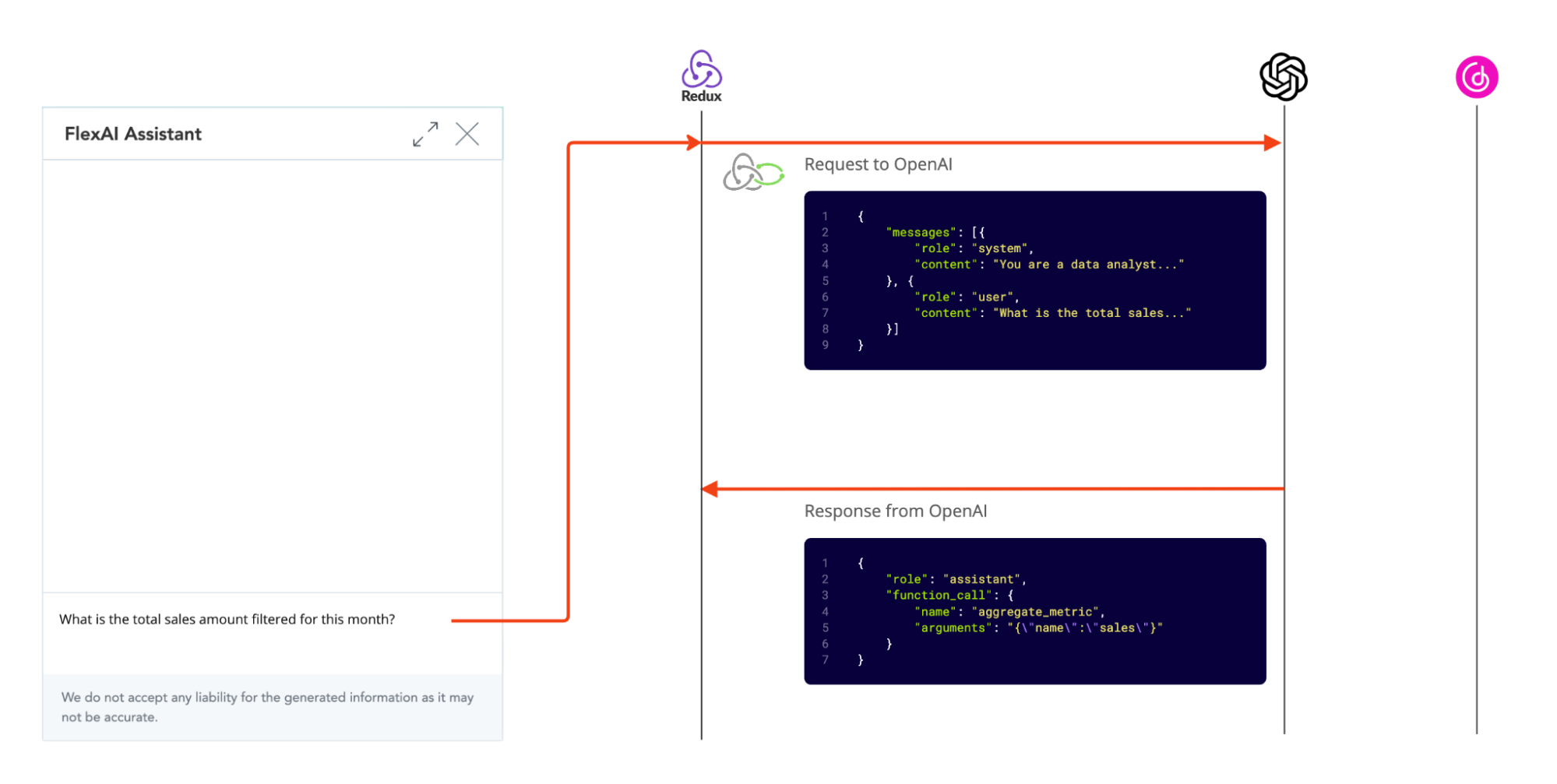
Step 2. Cooking the analytics
Now, let’s assume a more complex scenario - OpenAI has deduced that the user wants to see the aggregated metric. The language model can’t possibly know the answer to that, so it asks for a function call from our app.
Another middleware is triggered this time - the one that’s listening to the function calls. It executes the function and adds the result back to the store, as a new message.
Step 3. Serving the user
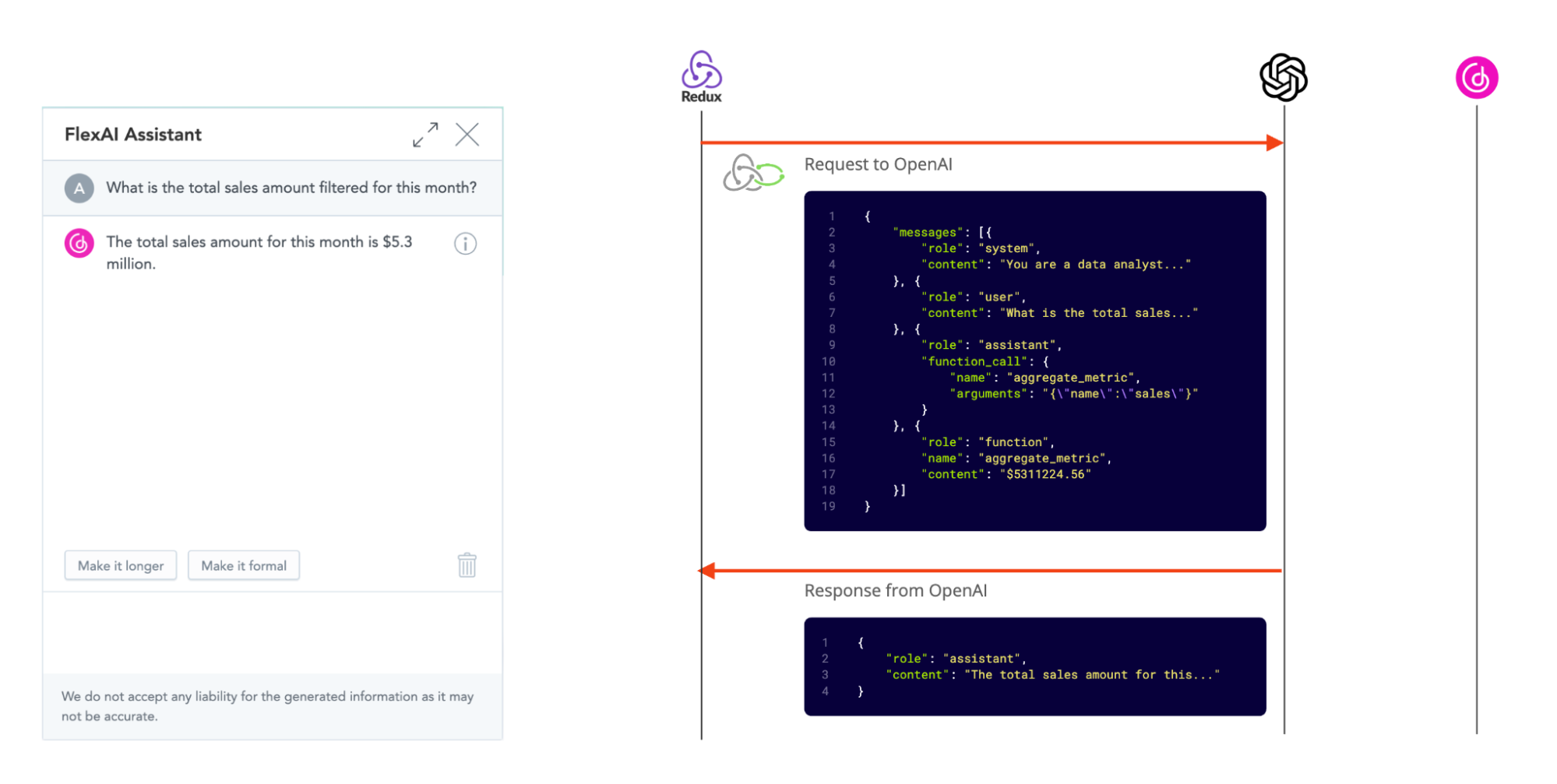
Finally, the middleware sends the function result back to the OpenAI server, along with a complete conversation history. We can’t send just the last message, as OpenAI would not have the necessary context to even know what the user’s question was. The API is stateless, after all. This time the assistant response is textual and does not trigger any middleware.
Meanwhile our frontend is showing only the messages that make sense to the user, i.e. user message itself and the textual response from the assistant. It can also derive the loading state right from the message stack - if the last message in stack is not a textual response to the user - we are in the loading state.
Are we there yet?
There is an old joke among UX folk about the perfect user interface. It should look like this:
A single huge green button that guesses and does exactly what the user wants. Unfortunately, we are not quite there yet. Generative AI is not a silver bullet that will replace the user interface as we know it, instead, it’s a useful and powerful addition to frontend engineer’s toolset. Here are a few practical pieces of advice on how to use this new tool.
Select the use cases carefully
Sometimes it’s still easier to just press a few buttons and check a few checkboxes. Don’t force the user to talk to AI.
An ideal application for the generative AI - a relatively simple, but tedious and boring task.
Don’t try to replace the user
Do not make decisions or take actions on the user's behalf. Instead, suggest a solution and let the user confirm any action explicitly. GenAI still makes mistakes quite often and needs supervision.
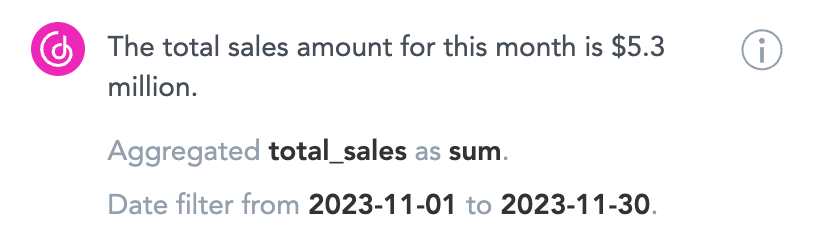
It’s also a good idea to provide the user with a way to quickly validate the AI assistant response. Ideally, without leaving the chat interface. We’ve solved it by adding an “explain” function that tells the user which exact metric and over what dimensions did we use to calculate the aggregation.
Keep it simple
A few simple dedicated assistants in strategic places of the app is better than one “do it all” chat bot. This means each assistant will have less background context to take into account, less functions that it can choose to call and ultimately will make less mistakes, will run faster and will be cheaper to operate.
Conclusions
These are exciting times to be a front-end engineer. Our colleagues from AI created a magnificent piece of technology and it’s now up to us to cook-up some delightful treats for our users.
Want to read more about the experiments we are running at GoodData? Check out our Labs environment documentation.
Want to enter the test kitchen yourself? Sign up for our GoodData Labs environment waitlist.
Want to talk to an expert? Connect with us through our Slack community.
Why not try our 30-day free trial?
Fully managed, API-first analytics platform. Get instant access — no installation or credit card required.
Get started
