Primary Key
A primary key is an attribute contained in a dataset in your logical data model (LDM) that does the following:
- It is a primary key of the dataset, which enables the system to distinguish individual records.
- It is an attribute that enables connecting this dataset to another one using its values to make a relationship.
Primary keys are important identifiers of uniqueness within a dataset.
To connect two datasets together, define a primary key in the first dataset and a reference (foreign key) in the second dataset. Together, they form a relationship - a one-directional mapping between a parent object and a child object that will reference the data in the parent object.
You can have only one primary key per dataset, but you can have multiple other datasets in the LDM with references to that primary key. Any single reference in a dataset can point back to only one primary key.
Note that the primary key can also be a composite key, that is itself created by concatenating multiple attributes together. A composite key is still treated as a single primary key (grain).
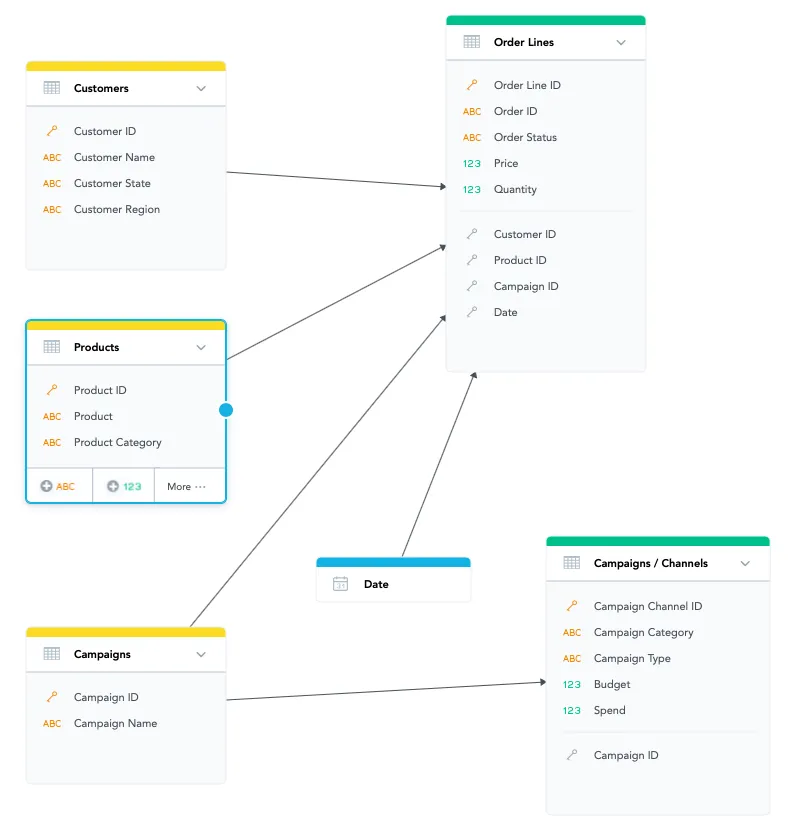
The direction of the arrow determines which dataset’s data can be analyzed (sliced) by the data from the other dataset.
For example, in the following LDM, the relationship between the Customer and Order Lines datasets allows you to slice Quantity by Customer Name.
Recommended Practices
Make sure that each value of a primary key is unique. If the data contains multiple rows with identical primary key values, you will experience wrong results in visualizations.
The values for the reference attribute do not have to be unique.
Maintain “referential integrity”: make sure that each value of the foreign key column in the referencing dataset has a corresponding value in the primary key column of the referenced dataset.
This is important because the query engine uses dataset relations in the LDM to connect the underlying database tables (technically, inner joins are used on SQL).