Aggregate Awareness
Aggregate Awareness is a performance feature in GoodData that automatically routes analytical queries to the most efficient dataset. Instead of always querying detailed fact tables, the engine can use pre-aggregated datasets when they are available and appropriate. This ensures faster dashboards, lower data warehouse costs, and a smooth end-user experience without requiring any changes to metrics or dashboards.
Dashboards can be built on aggregated data (for example, months by default), while still allowing drill-down into daily detail when permitted. Previously, dashboards always had to be built on the most detailed data to support drill-downs and filters, which impacted performance. With Aggregate Awareness, the engine can transparently use aggregated datasets for queries whenever possible.
Because of their significantly smaller row counts, queries against aggregate tables are much faster. For example: instead of scanning a billion rows in a detailed dataset, the engine can use a million rows in an aggregate, significantly reducing query times.
Benefits:
- Faster performance for large datasets.
- Lower warehouse costs by avoiding scans of high-granularity tables when not needed.
- Scalable embedded analytics that remain responsive even under high traffic.
- Reduced complexity: no need to duplicate metrics for different levels of aggregation.
- Supports tiered access models where customers may only be allowed to see aggregated views of the data.
- Works with both time-based aggregates and attribute-based aggregates (e.g., by product or brand).
How It Works
Data engineers define and maintain aggregate tables in their data warehouse (for example, daily, monthly, or quarterly summaries). GoodData does not aggregate data automatically, therefore you must prepare these aggregates in advance, using materialized views, ETL jobs, or other database tools, and then register them in the Logical Data Model (LDM).
When a user runs a query, the GoodData engine evaluates all datasets that can satisfy it. The dataset with the highest precedence value is selected. Precedence values are numeric and determine priority, i.e. higher numbers mean higher priority.
- Detail datasets (non-aggregated data) always have precedence 0, and this value cannot be changed.
- Aggregate datasets must be assigned precedence values higher than 0 to be considered.
- If multiple datasets share the same highest precedence (i.e. there is no dataset with higher precedence), the engine may pick any of them.
This precedence-based approach ensures that queries use the most efficient dataset available. For example, daily aggregates can be assigned precedence 1, monthly aggregates 2, and quarterly aggregates 3. A report aggregated by year could technically be satisfied by all four datasets (detail, daily, monthly, quarterly), but the quarterly dataset would be chosen thanks to its higher precedence value.
Aggregate Awareness works not only for time-based aggregates (days, months, quarters) but also for aggregates by other attributes, such as product or brand. The engine evaluates queries against available aggregate datasets and uses them whenever the required dimensions are supported.
When a filter is applied, the engine evaluates whether the aggregate dataset can still be used. If a filter requires more granular data (for example, daily detail), the engine switches to a more detailed table.
At this stage, Aggregate Awareness supports only additive metrics. This includes functions such as SUM, MIN, and MAX. Other types of calculations, for example COUNT DISTINCT or AVERAGE, are not yet compatible with aggregate datasets and will continue to run only against the detailed data.
Relationship to LDM and MAQL
Aggregate datasets are defined in the LDM. In MAQL, Aggregate Awareness works largely seamlessly: the same metric can be used at different levels of aggregation without additional configuration. Aggregate datasets also appear in the dataset list in the modeling environment, where they can be referenced when needed, but end users will not see them directly in the data catalog.
Configuration
Aggregate datasets can be configured in the LDM Modeler.
- Adding aggregated facts: When you click Add Field in a dataset, you can now define not only facts and attributes but also aggregated facts.
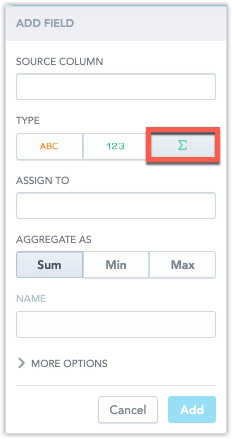
For each aggregated fact, you define a source fact (via the Assign to field) and choose an aggregation function (SUM, MIN, and MAX). Aggregated facts always reference a standard fact.
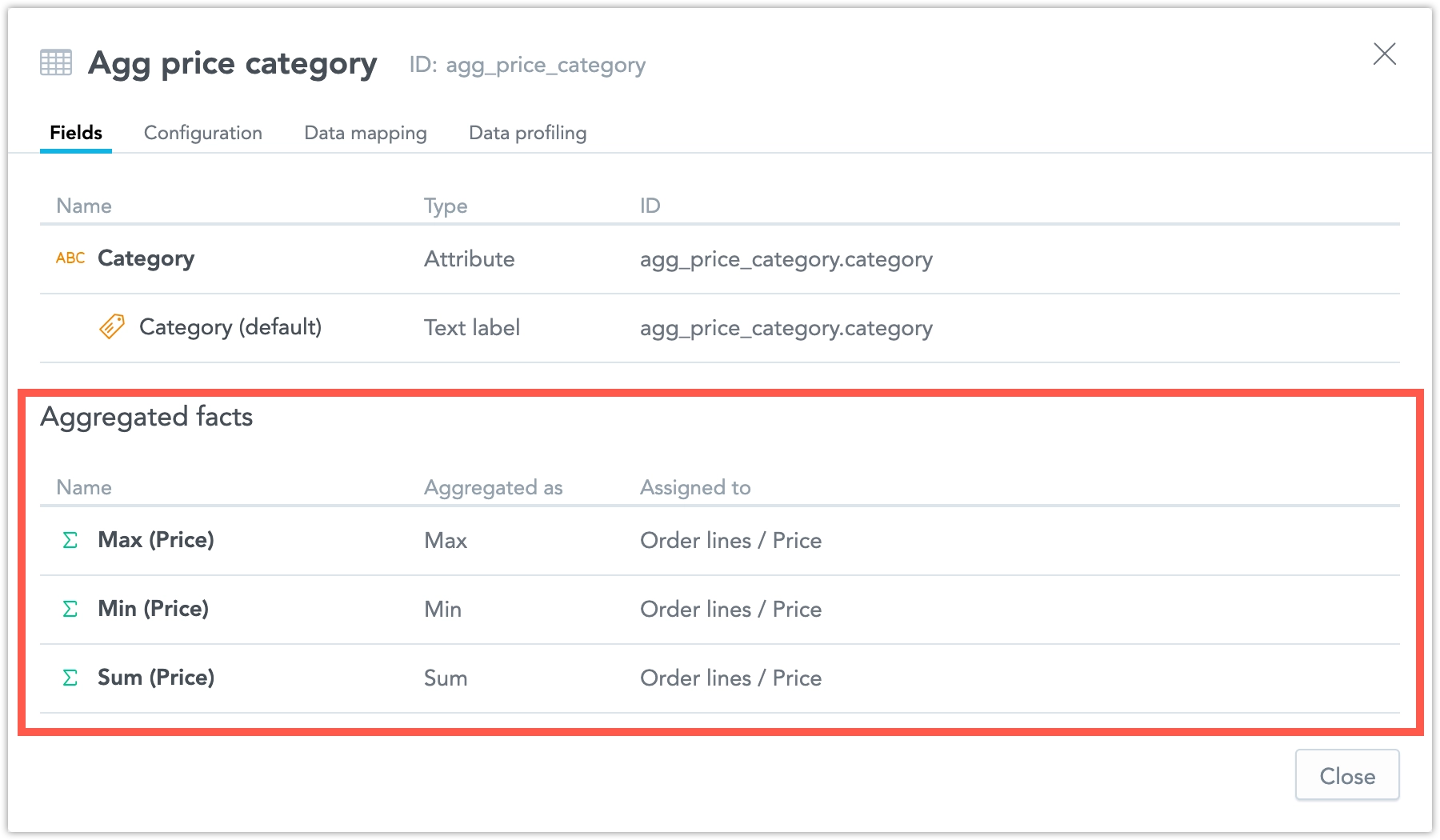
Fields tab: When you open a dataset’s detail in the LDM modeler, the Fields tab now lists all aggregated facts that have been created for that dataset. Each aggregated fact is displayed with its name, its aggregation method, and the fact it is assigned to.
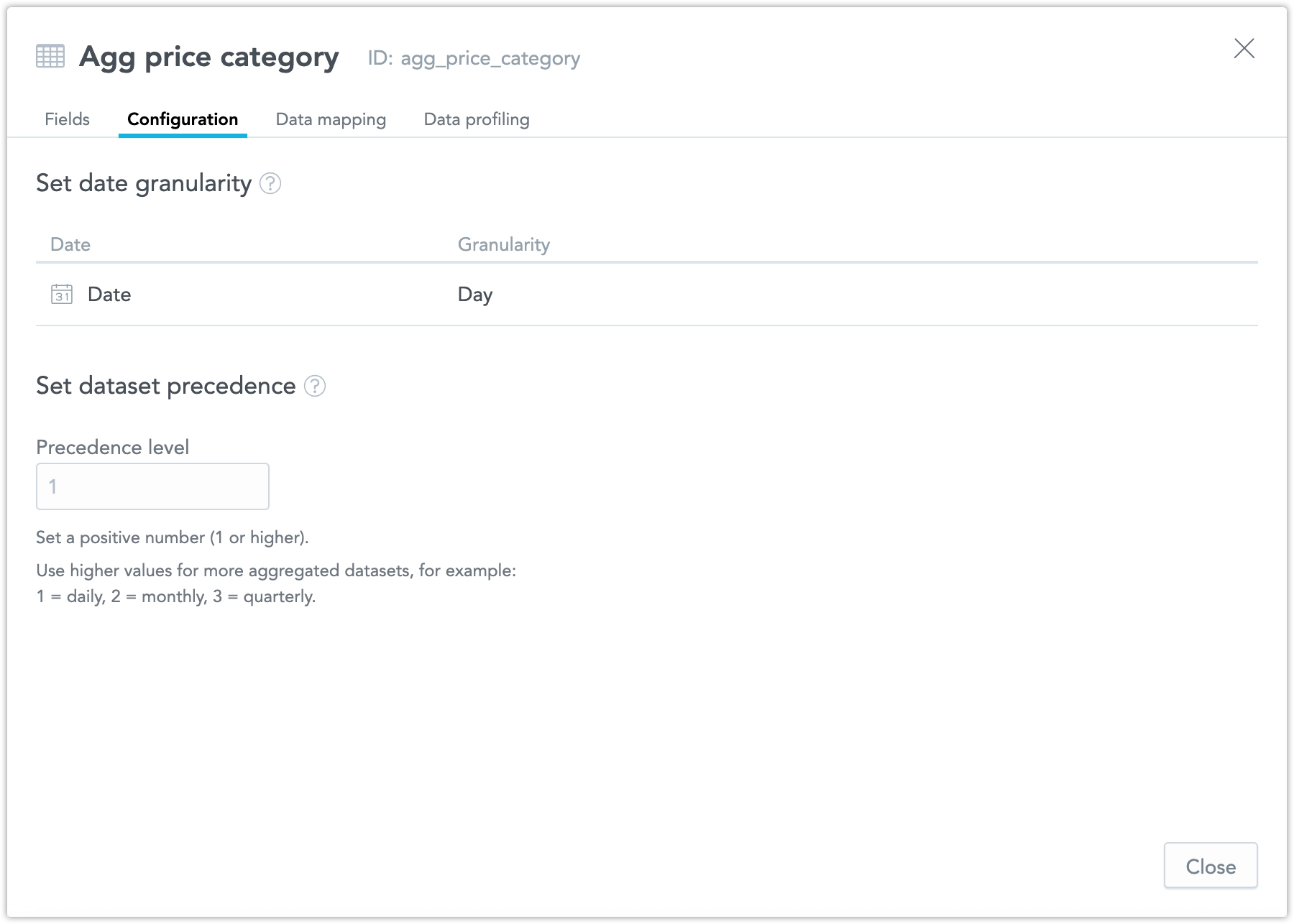
Configuration tab: This tab contains two new settings:
Granularity – defines the date granularity of the dataset.
Precedence – sets the priority of the dataset compared to others.
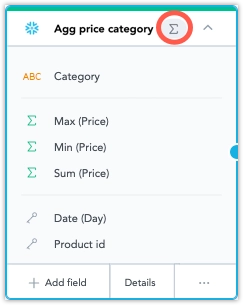
Dataset canvas: On the dataset canvas, an aggregate fact icon appears if a dataset contains aggregated facts. Hovering over the icon displays details about them.
Setting Date Granularity
Every aggregate dataset must have a date granularity setting that matches the way the data is stored in the data warehouse. Correctly configuring granularity is essential for the engine to select the right dataset.
- Use this only if your data is already aggregated.
- Example: If the table contains one row per day, set the granularity to Day.
- Setting a lower granularity (such as hour) adds no value.
- Setting a higher granularity (such as week or month) results in loss of information.
Granularity can also be used in datasets that are already aggregated at a certain level, even if they are not aggregated by timestamp. For example, a dataset may already be aggregated at the quarter level.
Security Considerations
Aggregate Awareness respects existing security filters, but with some differences:
- User Data Filters: If a user filter cannot be applied to an aggregate table, the engine falls back to the detail table. This ensures no data leaks.
- Workspace Data Filters: In this version, WDFs are not checked on aggregate datasets. The data model author is responsible for applying WDFs consistently both to the fact dataset and to all aggregate datasets. If WDFs are missing on an aggregate dataset, that dataset cannot be safely used for queries requiring workspace-level filtering.
Best Practices
- Always align dataset granularity with how the data is stored.
- Assign clear and distinct precedence values across aggregates.
- Use aggregate tables for the most common reporting levels (day, month, quarter) to maximize impact.
- Consider creating aggregates by attributes (e.g., brand, product) for frequently used filters.
- Use materialized views or ETL processes to create efficient aggregates in your data warehouse. Many databases support materialized views that automatically maintain aggregates over time.
- Attribute placement: Do not define attributes directly in a fact dataset if you plan to use Aggregate Awareness. Instead, create a dimension dataset for the attribute and connect it both to the original fact dataset and to the aggregate dataset. This ensures the attribute is available consistently across all levels of detail.
User Experience
For end users, Aggregate Awareness is seamless. They build dashboards and metrics the same way they always have. During query execution, the engine automatically chooses the dataset that best matches the required granularity and precedence.
- Dashboards and KPIs load faster when aggregates are used.
- Drill-downs remain consistent: a user can drill from a monthly chart to daily detail using the same metric, with no reconfiguration required.
- Workflow does not change: end users will only notice improvements in speed and consistency.
Aggregate datasets are not exposed in the data catalog. Users only see the original fact dataset, and the engine uses aggregate datasets internally. This prevents clutter in the data catalog, even if many aggregate datasets exist.
Limitations
- Non-additive metrics (such as
COUNT DISTINCTorAVERAGE) are not supported in the current version. - Precedence must be configured carefully. If multiple aggregate datasets have the same precedence, selection may be random.