Advanced Modelling Use Cases
Every database is different, and sometimes one or more of the following edge case scenarios may need to be considered when modelling the data.
Multiple Datasets Mapped to the Same Table
This is typically needed when one table represents multiple logical entities, and each entity should be represented by a separate dataset in the LDM.
While the LDM Modeler supports mapping of multiple datasets to the same table, publishing an LDM with such mapping fails.
To avoid this issue, create multiple views on top of the table and map each dataset to a separate view.
For example, you have two tables, users and tickets.
- The
userstable contains ticket creators and assignees. - The
ticketstable contains theassignee_idandcreator_idcolumns.
To avoid mapping multiple datasets to the users table, do the following:
- In the database, create two views on top of the
userstable:v_users_assigneesandv_users_creators. - In the LDM, create three datasets:
assignees,creators, andtickets. - Map the
ticketsdataset to theticketstable. - Map the
assigneesdataset to thev_users_assigneesview. - Map the
creatorsdataset to thev_users_creatorsview. - Create a relationship from the
assigneesdataset to the theticketsdataset using theassignee_idcolumn as a primary key in theassigneesdataset. - Create a relationship from the
creatorsdataset to theticketsdataset using thecreator_idcolumn as a primary key in thecreatorsdataset.
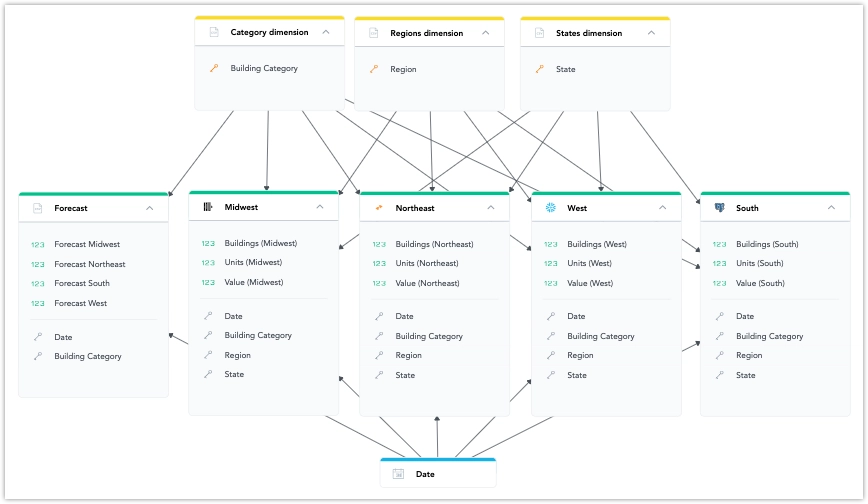
Using Multiple Data Sources in an LDM
- You can use datasets from different data sources in an LDM. They can be connected using common attribute or date dimension datasets.
- The list of data sources prioritizes those already used in the current model. You can change the data source in dataset mapping.
Limitations
- Using multiple data sources in an LDM is not compatible with the Unique Data Sources for Tenants feature.
Understanding Data Federation, Data Blending, and Data Joins
Data Federation:
Data federation creates a virtual layer that lets users access and query data from multiple sources without moving or copying it.Data Blending:
Data blending combines specific subsets of data from multiple sources for analysis in a single visualization.Data Joins:
The key difference between data blending and traditional joins is the timing of the operation:- In traditional joins, the join is usually performed before aggregation within the database.
- In data blending, the operation is typically applied after aggregation, using data that has already been processed from different sources.
Blending Data from Multiple Sources in a Single Visualization
You can create visualizations that use multiple metrics from different data sources. These metrics are blended into one common result set using shared conformed dimension attributes. This approach allows you to connect data from multiple sources in real-time, giving you a complete view of your business without the need for complex data movement.
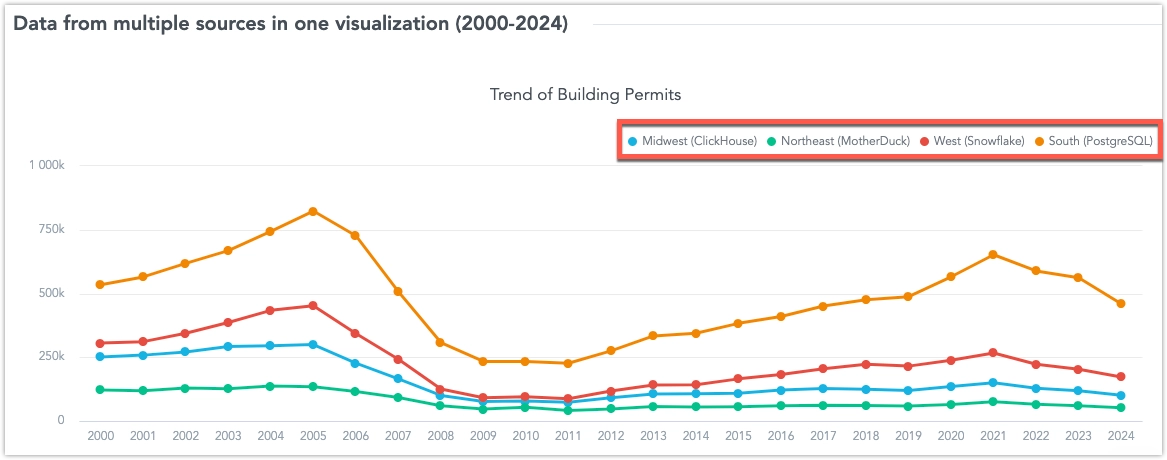
The common attributes can be:
- An attribute of a date dimension dataset referenced in each data source used for data blending.
- An attribute defined as a primary key in a dimension dataset, present as a foreign key in each data source used for data blending.
These common dimension attributes can be used for breaking down metrics, grouping, slicing, or filtering in a visualization that uses blended data.
Attributes are defined by their primary label (e.g., Federal Information Processing Standard state code). Optionally, you can define a secondary label (e.g., a user-friendly display name like “California”) in the dimension dataset. In this case, blended visualizations will display this label, even if the secondary label is not present in all data sources.
However, using secondary labels for common attributes requires retrieving all dimension attribute values during queries, which can slow down processing. For this reason, we recommend avoiding secondary labels for attributes with high cardinality.
Limitations
Metrics from different sources can only be sliced or filtered using attributes that are:
- References to common dimension datasets.
- Present in each data source involved in the visualization.
Only fact-based metrics can be used.
The Show as Percent feature works only with a single non-date attribute.
A fact table can be directly linked to a dataset, but there can only be one data source change in a single path of relationships.
For example:
Country (Snowflake) -> County (BigQuery) -> City (Snowflake) -> Facts (Snowflake)
In this example, the path changes data sources twice (from Snowflake to BigQuery and back to Snowflake), which is not supported.
NULL Joins
You can define null-handling behavior for selected logical data model (LDM) objects using the isNullable and nullValue fields.
These fields are available for facts, aggregated facts, attributes, labels, and reference sources. They affect join behavior so that NULL = NULL evaluates to true in full outer join conditions, in contrast to standard database behavior, where NULL = NULL evaluates to false.
Important
Currently, isNullable and nullValue affect join behavior only when enableNullJoins is enabled. If that setting is disabled, standard database behavior is used.
These fields currently apply to full outer join conditions.
Supported LDM Objects
You can use these fields on the following LDM object types:
- fact
- aggregated fact
- attribute
- label
- reference source
isNullable
The isNullable field is an optional boolean that describes whether the underlying database column can contain NULL values.
Possible values:
true: the database column can containNULLfalse: the database column does not containNULLnullor omitted: the nullability of the database column is unknown
This field describes the expected nullability of the source column. If it is not provided, the platform does not assume whether the column allows NULL.
Example
{
"id": "order_status",
"type": "attribute",
"sourceColumn": "order_status",
"isNullable": true
}nullValue
The nullValue field is an optional string that defines which value should replace NULL in join conditions. If nullValue is set, the join condition is rewritten to use COALESCE:
COALESCE(column1, nullValue1) = COALESCE(column2, nullValue2)If nullValue is not set, the platform uses a database-specific null-safe comparison function instead, such as:
EQUAL_NULL(column1, column2)This lets full outer joins match rows where both joined values are NULL, when null joins are enabled.
Example
{
"id": "customer_region",
"type": "attribute",
"sourceColumn": "region",
"isNullable": true,
"nullValue": "UNKNOWN"
}How Null-Safe Joins Work
When enableNullJoins is enabled, null handling in full outer joins changes from standard SQL behavior.
Standard behavior:
NULL = NULLThis evaluates to false.
With null joins enabled, rows with NULL values in both joined columns can match. This is done in one of these ways:
- by replacing
NULLwith the configurednullValueand comparing the results - by using a database-specific null-safe comparison function when
nullValueis not set
For example, this illustrates how changing the setting impacts Snowflake’s behavior (similarly affecting other databases):
Example Without nullValue
EQUAL_NULL(customer.country, store.country)Example With nullValue
COALESCE(customer.country, 'UNKNOWN') = COALESCE(store.country, 'UNKNOWN')In both cases, rows with missing values on both sides can be treated as matching when null joins are enabled.
Format Requirements for Date and Timestamp Values
If you use nullValue with date or timestamp columns, the value must use the correct format:
- dates:
yyyy-mm-dd - timestamps:
yyyy-mm-dd hh:mm:ss
Date Example
{
"id": "ship_date",
"type": "label",
"sourceColumn": "ship_date",
"isNullable": true,
"nullValue": "2099-12-31"
}Timestamp Example
{
"id": "processed_at",
"type": "label",
"sourceColumn": "processed_at",
"isNullable": true,
"nullValue": "2099-12-31 23:59:59"
}Period Granularity Behavior
If period granularity is required and nullValue is set, the configured value is not used directly. In this case, nullValue is replaced with -1. This applies regardless of the actual configured string value.
When to Use These Fields
Use isNullable and nullValue when your model includes columns that can contain missing values and you need full outer joins to treat missing values on both sides as matching.
This is especially useful when:
- related records may be missing dimension values in multiple tables
- you need predictable join behavior for incomplete source data
- you want to control how
NULLvalues are handled in join conditions