Cache Management
When analyzing your data, you can choose between caching data using FlexCache or bypassing the cache and using direct queries. Each option is tailored to different project needs.
FlexCache enhances query speed and reduces costs by storing query results in memory, eliminating the need to repeatedly access the database and significantly boosting performance by reducing data retrieval times. It also offers cost efficiency, potentially saving over 50% on cloud data warehouse operational costs due to reduced query frequency. Its integration with GoodData’s security model further guarantees that data delivery is both fast and secure, making it an ideal choice for handling large volumes of data efficiently.
Direct query accesses live data, providing the most up-to-date analytics at the cost of speed and increased operational costs. This method is beneficial when real-time data updates are crucial for your analytics.
FlexCache
GoodData creates data caches to store queried data and to optimize performance. When GoodData queries a data source, the latency and concurrency depends on what data source technology you are using. However, when querying caches, we can support any data volume with very low latency and very high concurrency, up to the memory resource limit set in our cache storage.
FlexCache Architecture Diagram
This diagram explains how the FlexCache architecture works:
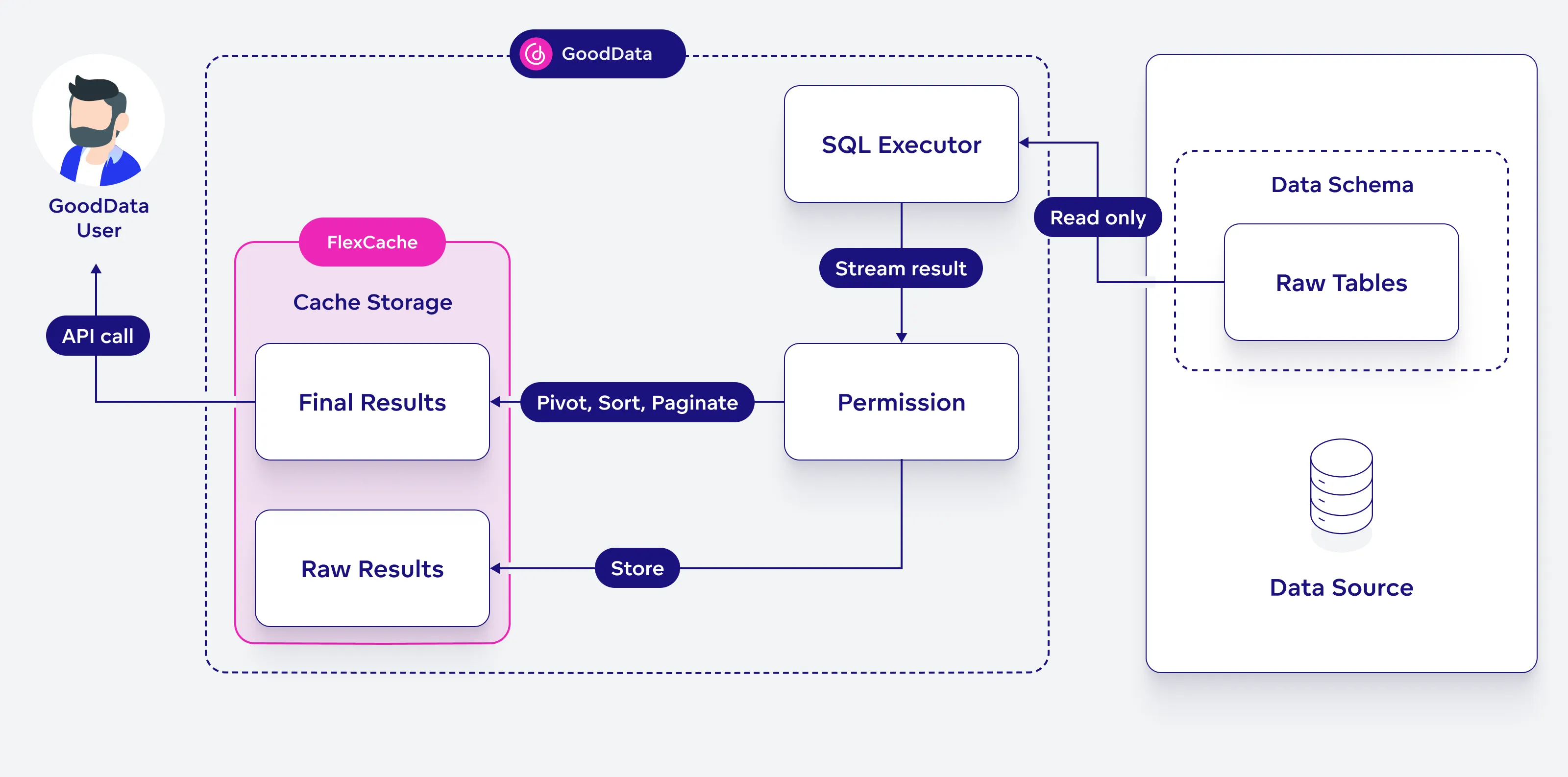
A GoodData user sends an API request to get data. The system first checks the cache storage, which holds both raw and final results.
- If the result is already in the cache, it is returned immediately.
- If the result is not in the cache, an SQL executor runs a query on the raw tables in the data source.
- The response from the query goes through permission checks and then splits into two steps:
- One copy is saved in FlexCache as raw data.
- The other copy is processed (e.g., pivoted, sorted, or paginated) and then sent back as final results to the user.
Note that after a new Extract, Load, Transform (ELT) is executed on the source data, you need to invalidate existing caches to ensure that the updated data is queried by GoodData. Refer to the Cache Invalidation section below for more information.
GoodData makes use of up to three data caches:
Final Query Results
Processed raw query results that have been sorted, pivoted and paginated. This cache is used to display data in your visualizations.
You can also access this cached data directly using the /api/v1/actions/workspaces/{workspaceId}/execution/afm/execute API endpoint to get resultId which can then be browsed using the /api/v1/actions/workspaces/{workspaceId}/execution/afm/execute/result/{resultId} API endpoint.
Raw Query Results
This cache stores the raw result of a query before any processing is applied. These results are not paginated, all rows are aggregated together up to the platform limit.
The raw results cache is used to recompute the final results cache when you perform certain actions with the data; For example, inside visualizations, when you change how the data is sorted or when you pivot the data by adding an attribute into columns.
Cache Invalidation
Whenever an ELT finishes, you need to perform cache invalidation to dump the outdated stored result and query new data. To invalidate a cache, see Invalidate Cached Data. The API endpoint updates the dataSource.uploadId attribute when a change happens. Caches with an outdated dataSource.uploadId attribute are dumped.
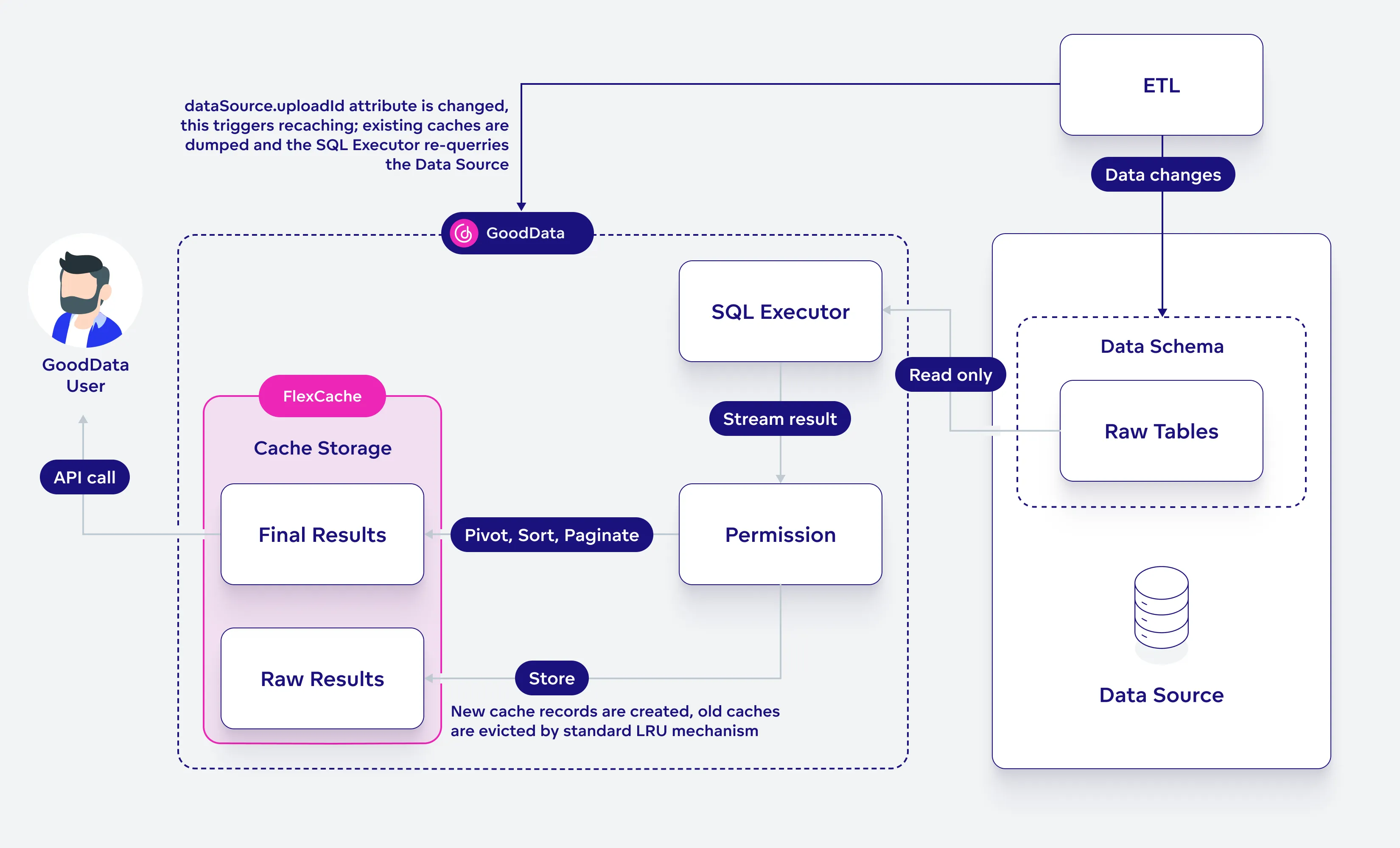
Caches have no time to live (TTL) expiration set, they are evicted based on the least recently used (LRU) cache replacement policy.
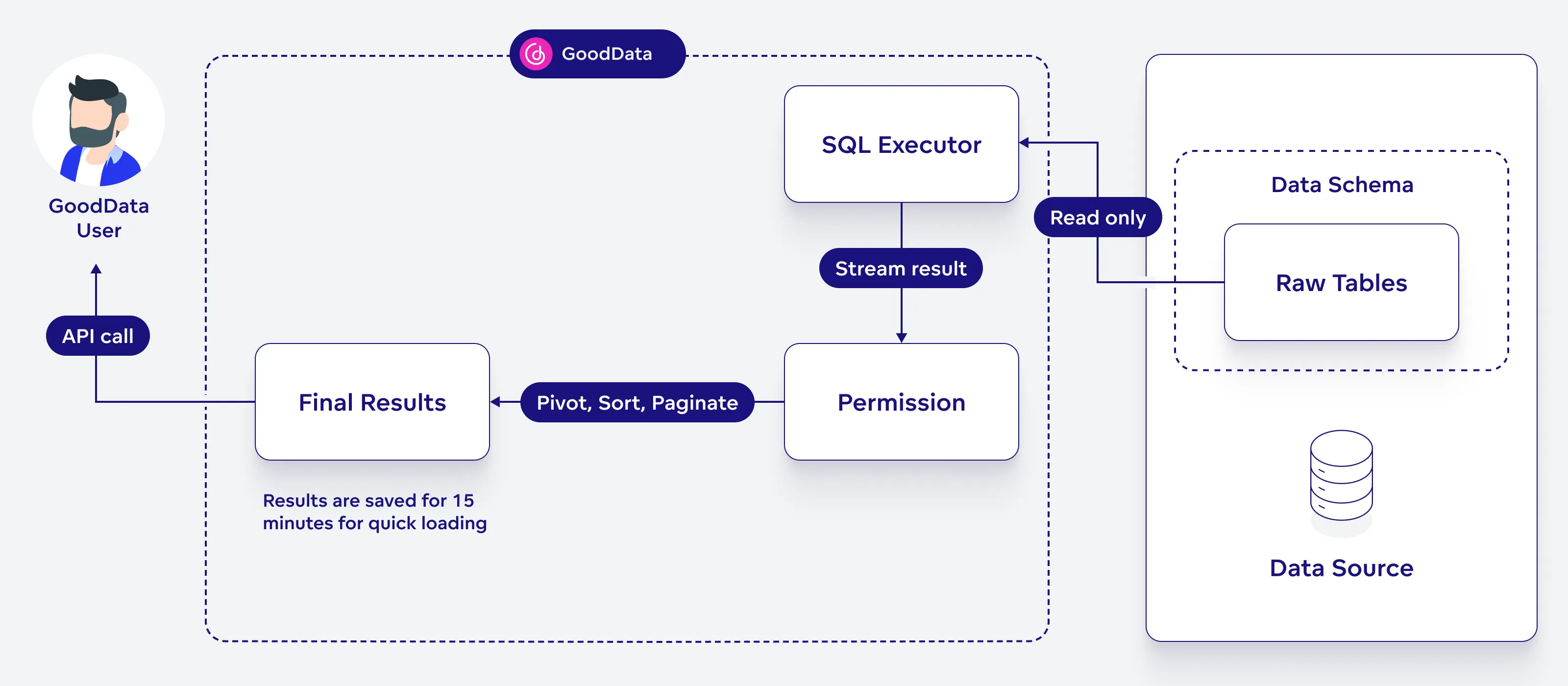
Direct Query
The caching of raw results is turned off and bypassed, allowing all data to be accessed live. However, calculations for analytics are briefly saved to load faster, but get updated whenever you refresh your dashboard.
This option is useful if you need instant updates to your analytics, as each query directly interacts with the database to provide real-time data. However, be aware that this method may lead to slower performance and higher costs.
To enable this option, follow the steps described in the Configuring Your Cache Preference section.
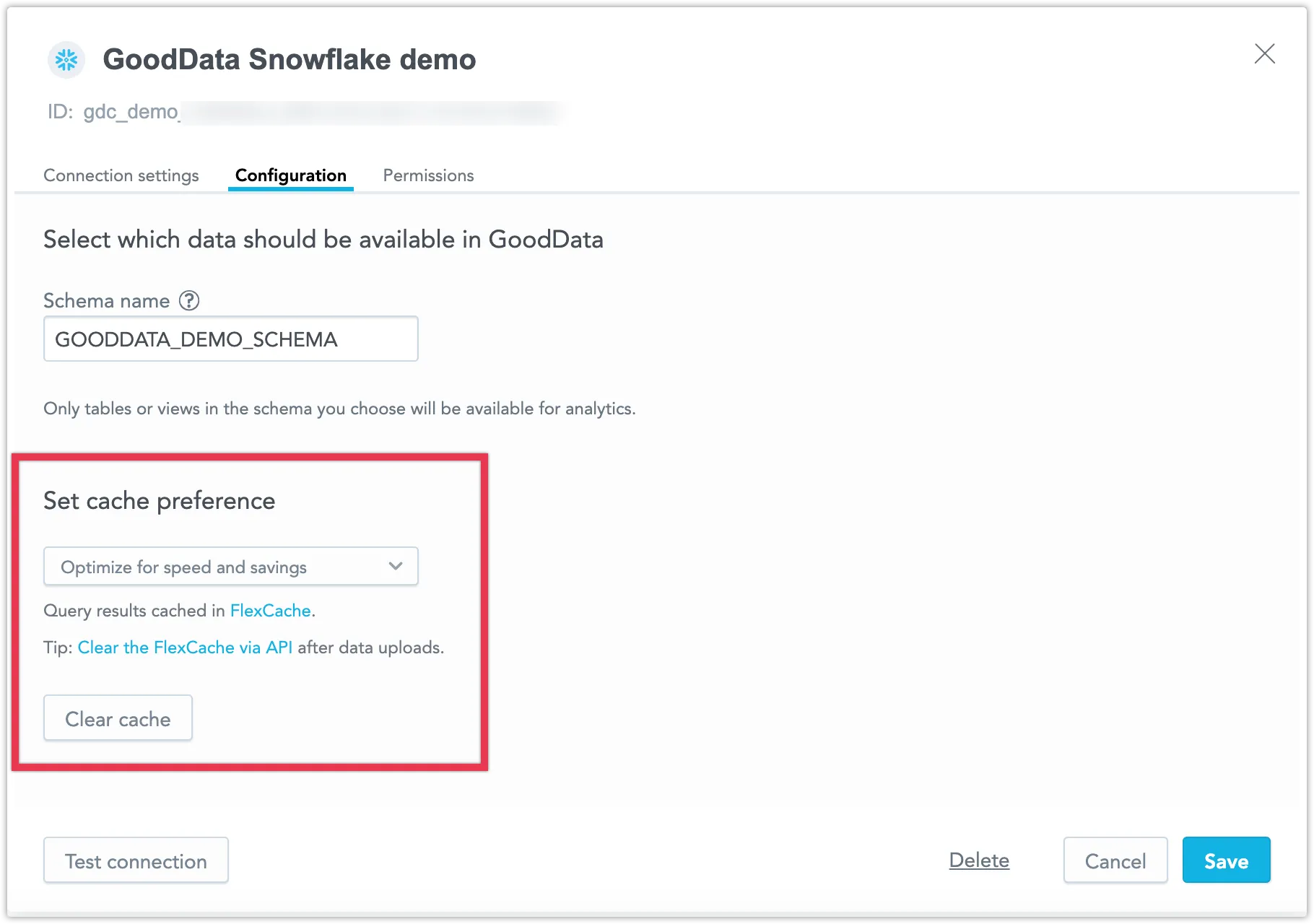
Configuring Your Cache Preference
When you add a new data source, you can choose your caching preference. Select from the following options:
- Optimize for speed and savings to enable FlexCache.
- Optimize for real-time data to utilize direct queries.
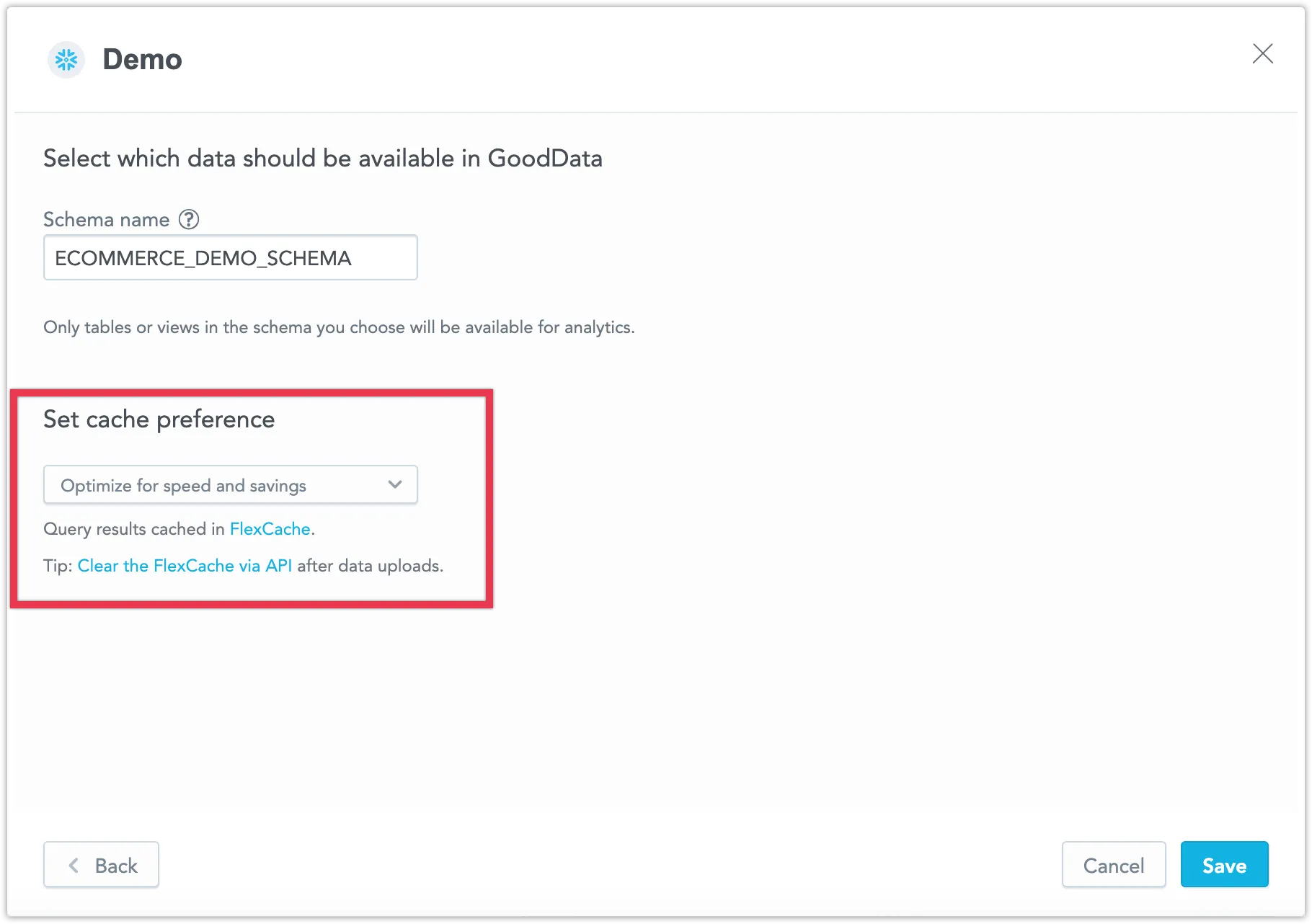
To modify the caching settings of an existing data source, follow these steps:
- Go to Data Sources.
- Open the data source you wish to edit.
- Click Configuration.
- Choose one of the options mentioned above.