Create an Amazon Redshift Data Source
Follow these steps to connect to Amazon Redshift and create an Amazon Redshift data source:
Refer to Additional Information for additional performance tips and information about Amazon Redshift feature support.
Configure User Access Rights
We recommend creating a dedicated user and user role specifically for integrating with GoodData.
Steps:
Create a user role and grant it the following access rights:
GRANT USAGE ON SCHEMA {schema_name} TO ROLE {role_name}; GRANT SELECT ON ALL TABLES IN SCHEMA {schema_name} TO ROLE {role_name};Create a user and assign them the user role:
GRANT ROLE {role_name} TO USER {user_name};Make the user role default for the user:
ALTER USER {user_name} SET DEFAULT_ROLE={role_name};If you use AWS Identity and Access Management (IAM) for Redshift authentication, do the following:
Create an IAM role or user with permissions to call
GetClusterCredentials(see https://docs.aws.amazon.com/redshift/latest/mgmt/generating-iam-credentials-role-permissions.html).(Optional) Create a database user and database groups (see https://docs.aws.amazon.com/redshift/latest/mgmt/generating-iam-credentials-user-and-groups.html).
Create an Amazon Redshift Data Source
Once you have configured your Amazon Redshift user’s access rights, you can proceed to create an Amazon Redshift data source that you can then connect to.
Steps:
On the home page switch to Data sources.
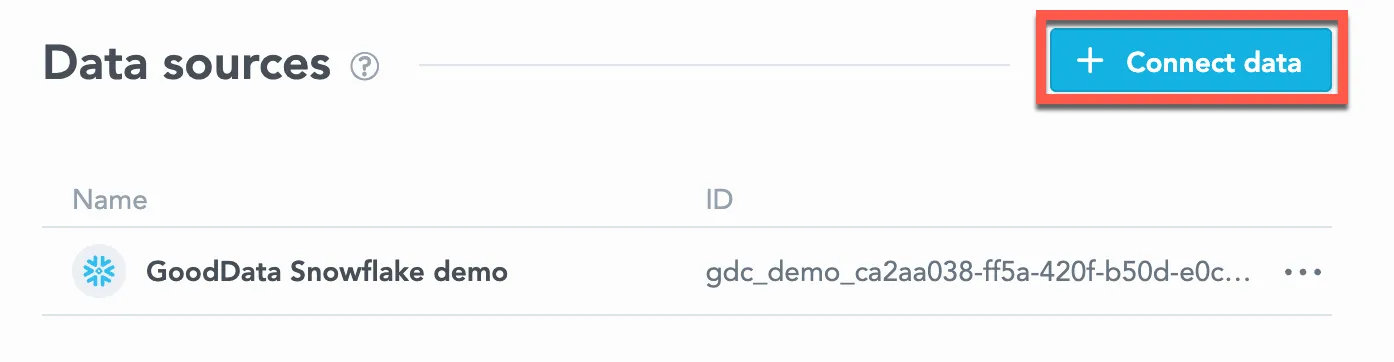
Click Connect data.
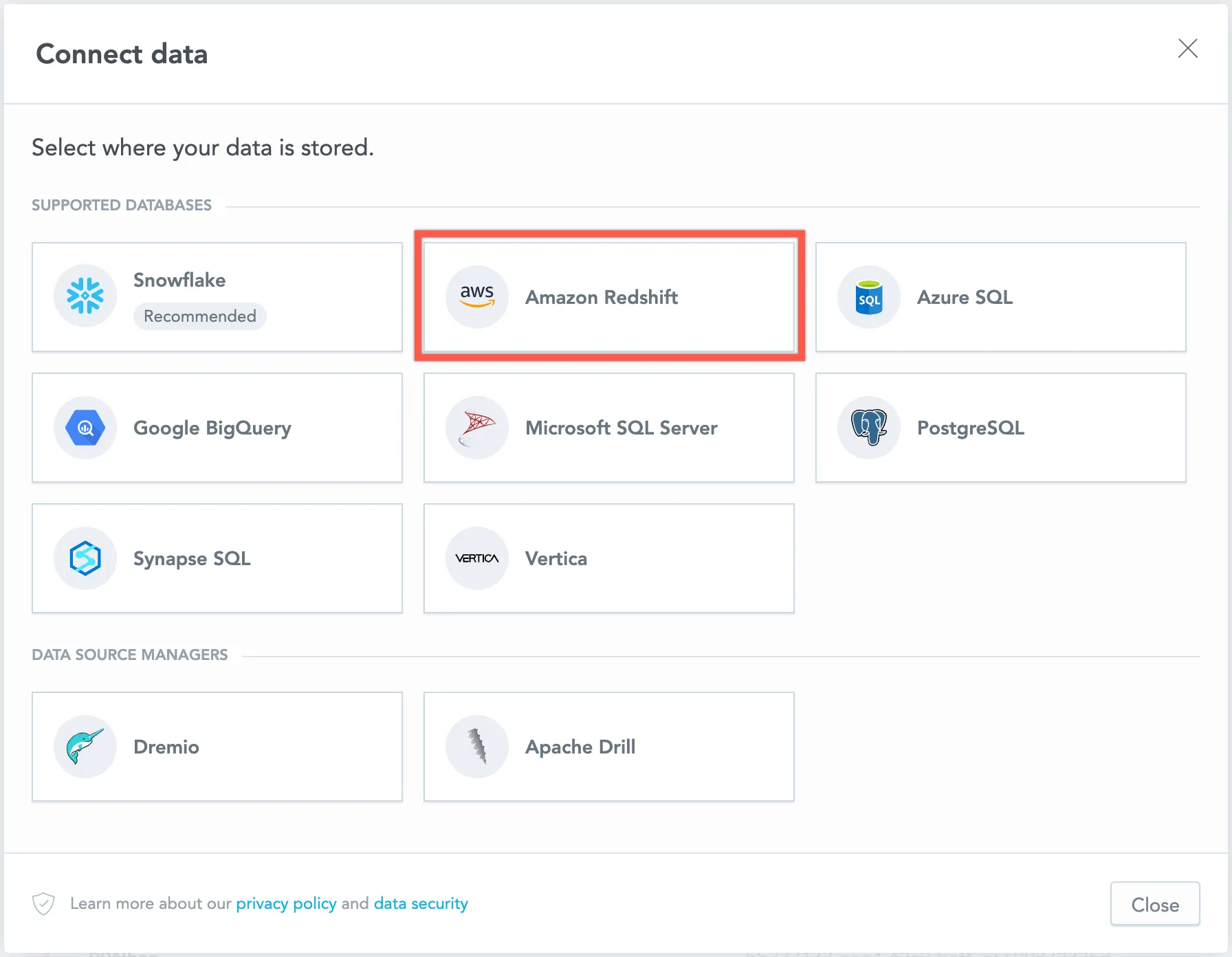
Select Amazon Redshift.
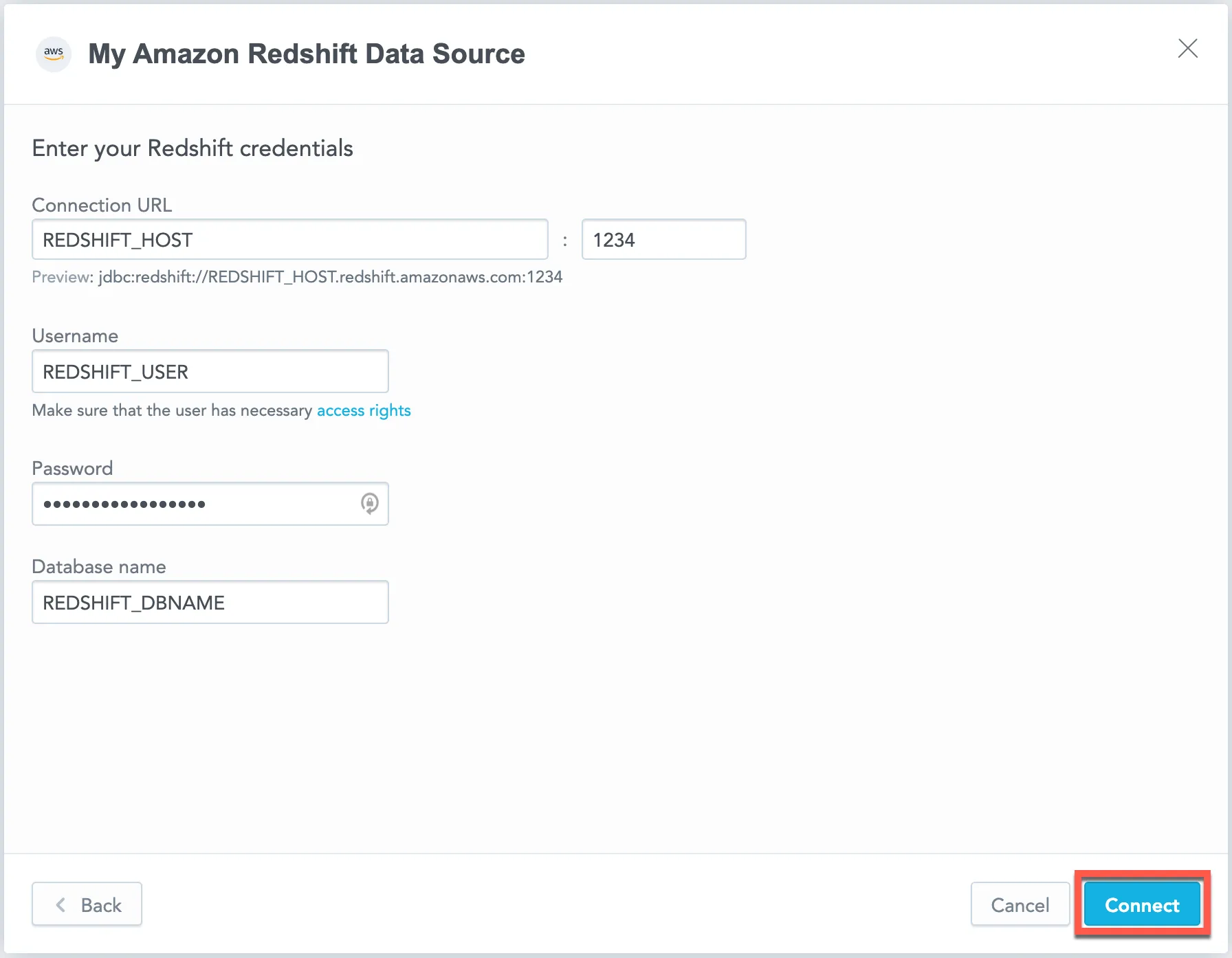
Name your data source and fill in your Amazon Redshift credentials and click Connect:
Input your schema name and click Save:
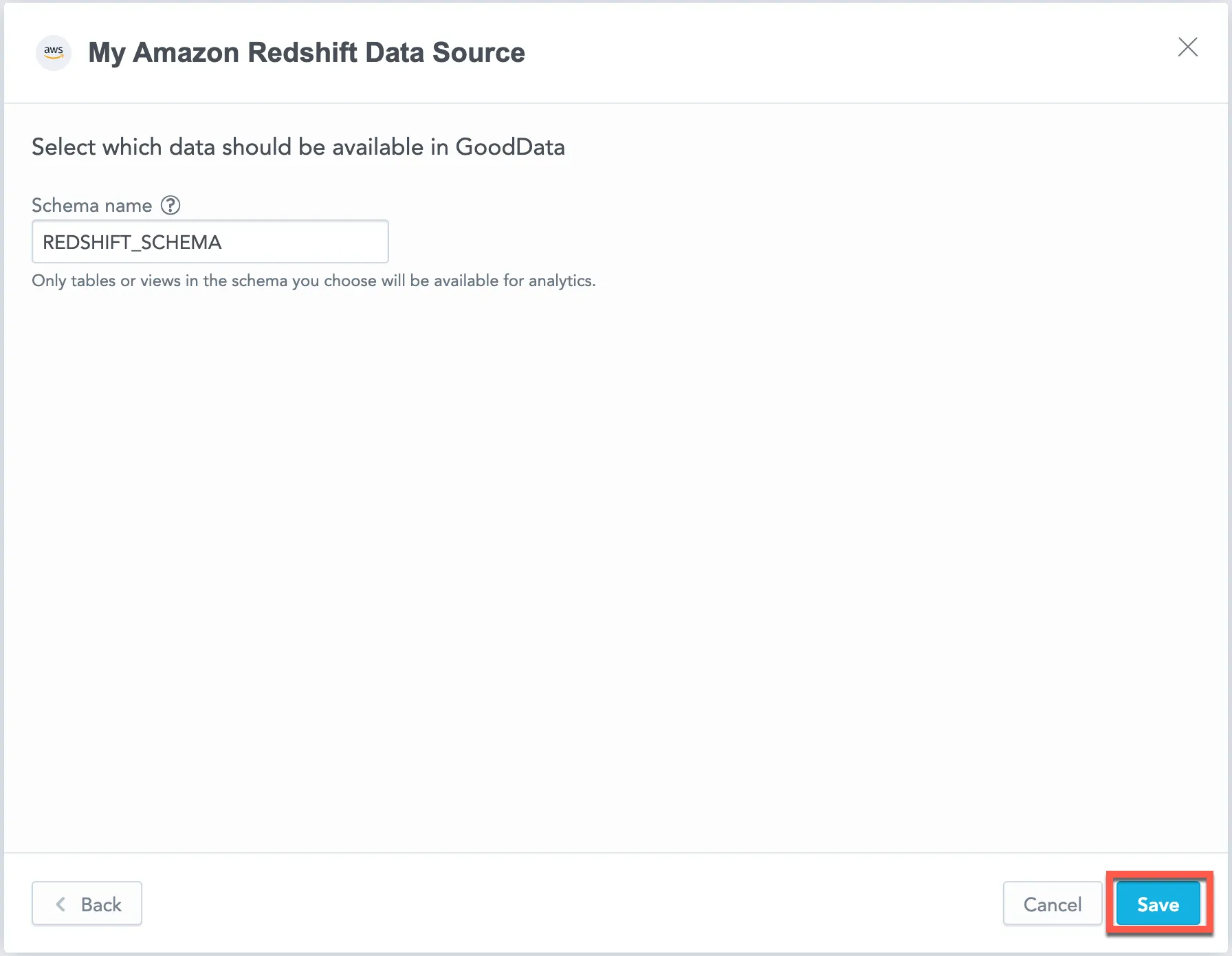
Your data source is created!

Steps:
Create an Amazon Redshift data source with the following API call:
curl $HOST_URL/api/v1/entities/dataSources \ -H "Content-Type: application/vnd.gooddata.api+json" \ -H "Accept: application/vnd.gooddata.api+json" \ -H "Authorization: Bearer $API_TOKEN" \ -X POST \ -d '{ "data": { "type": "dataSource", "id": "<unique_id_for_the_data_source>", "attributes": { "name": "<data_source_display_name>", "url": "jdbc:redshift://<REDSHIFT_HOST>:5432/<REDSHIFT_DBNAME>", "schema": "<REDSHIFT_SCHEMA>", "type": "REDSHIFT", "username": "<REDSHIFT_USER>", "password": "<REDSHIFT_PASSWORD>" } } }' | jq .To confirm that the data source has been created, ensure the server returns the following response:
{ "data": { "type": "dataSource", "id": "<unique_id_for_the_data_source>", "attributes": { "name": "<data_source_display_name>", "url": "jdbc:redshift://<REDSHIFT_HOST>:5432/<REDSHIFT_DBNAME>", "schema": "<REDSHIFT_SCHEMA>", "type": "REDSHIFT", "username": "<REDSHIFT_USER>" } }, "links": { "self": "$HOST_URL/api/v1/entities/dataSources/<unique_id_for_the_data_source>" } }
Create an Amazon Redshift data source with the following API call:
from gooddata_sdk import GoodDataSdk, CatalogDataSource, BasicCredentials
host = "<GOODDATA_URI>"
token = "<API_TOKEN>"
sdk = GoodDataSdk.create(host, token)
sdk.catalog_data_source.create_or_update_data_source(
CatalogDataSourceRedshift(
id=data_source_id,
name=data_source_name,
db_specific_attributes=RedshiftAttributes(
host=os.environ["REDSHIFT_HOST"],
db_name=os.environ["REDSHIFT_DBNAME"]
),
schema=os.environ["REDSHIFT_SCHEMA"],
credentials=BasicCredentials(
username=os.environ["REDSHIFT_USER"],
password=os.environ["REDSHIFT_PASSWORD"],
),
)
)
Additional Information
Ensure you understand the following limitations and recommended practice.
Data Source Details
The JDBC URL must be in the following format:
jdbc:redshift://<host>:<port>/<databaseName>Basic authentication is supported. Specify
userandpassword.If you use native authentication inside your cloud platform (for example, Google Cloud Platform, Amazon Web Services, or Microsoft Azure), you do not have to provide the username and password.
GoodData uses up-to-date drivers.
Unsupported Features
GoodData does not support the following features:
- Statistical functions:
regr_sloperegr_interceptcovar_sampcorrregr_r2
- Statistical running functions:
stdevstdevpvarvarp
- Window functions (running aggregations like
RUNSUM,RUNMAXorRUNVARP) with unbounded beginning of frames. - The Show missing values feature is not supported for visualizations when using a Redshift data source.
Known Issues
SQL Commands and Filtering
Redshift, MSSQL, AzureSQL, and SynapseSQL databases remove trailing spaces in
WHEREandHAVINGSQL commands, potentially affecting dashboard and workspace data filter functionality. For example, the commandSELECT * FROM table WHERE column = 'value 'would return both'value'and'value '(with a trailing space). Other databases retain trailing spaces in values.
Performance Tips
If your database holds a large amount of data, consider the following practices:
Denormalize the relational data model of your database.
This helps avoid large JOIN operations. Because Amazon Redshift is a columnar database, queries read only the required columns and each column is compressed separately.
- Use the columns that are most frequently used for JOIN and aggregation operations. Those columns are typically mapped to attributes that are most frequently used for aggregations in visualizations.
- If you have to build analytics for multiple mutually exclusive use cases, prepare a separate table for each use case.
Choose the best distribution style. At least, use a column with high cardinality so that loaded data is evenly distributed in your cluster.
Spin up databases/clusters based on user needs.
- Users with similar needs populate data into caches that are likely reused.
- Isolate data transformation operations running in your database from the analytics generated by GoodData.
Because Amazon Redshift does not support partitioning, use a related
DATEorTIMESTAMPcolumn as one of the sort keys to improve performance of visualizations using only the recent data.
Query Timeout
The default timeout value for queries is 160 seconds. If a query takes longer than 160 seconds, it is stopped. The user then receives a status code 400 and the message Query timeout occurred.
Query timeout is closely related to the ACK timeout. For proper system configuration, the ACK timeout should be longer than the query timeout. The default ACK timeout value is 170 seconds.
Permitted parameters
A Redshift data source URL can include parameters set apart by the ? and ; characters. Parameters are usually separated by & and ;. However, we have removed the ; separator for both purposes. Therefore, URL parameters should only be separated from the rest of the URL using ? and individual parameters should be separated exclusively with &.
- adaptiveFetch
- adaptiveFetchMaximum
- adaptiveFetchMinimum
- allowEncodingChanges
- ApplicationName
- assumeMinServerVersion
- autosave
- binaryTransferDisable
- binaryTransferEnable
- cleanupSavepoints
- connectTimeout
- currentSchema
- defaultRowFetchSize
- disableColumnSanitiser
- escapeSyntaxCallMode
- gssEncMode
- hostRecheckSeconds
- loadBalanceHosts
- localSocketAddress
- loggerFile
- loggerLevel
- loginTimeout
- logServerErrorDetail
- logUnclosedConnections
- maxResultBuffer
- options
- preferQueryMode
- preparedStatementCacheQueries
- preparedStatementCacheSizeMiB
- prepareThreshold
- readOnly
- receiveBufferSize
- reWriteBatchedInserts
- sendBufferSize
- socketFactory
- socketFactoryArg
- socketTimeout
- ssl
- sslfactoryarg
- sslhostnameverifier
- sslmode
- sslpassword
- sslpasswordcallback
- sslrootcert
- targetServerType
- tcpKeepAlive