Data Source Manager
Data Source Managers (DSM) manage the operation of other Data Sources. You can use DSMs to connect to Data Sources that GoodData does not support, or you can use them to federate information from multiple data sources in one workspace. Alternatively, you can federate data sources using our Data Blending feature.
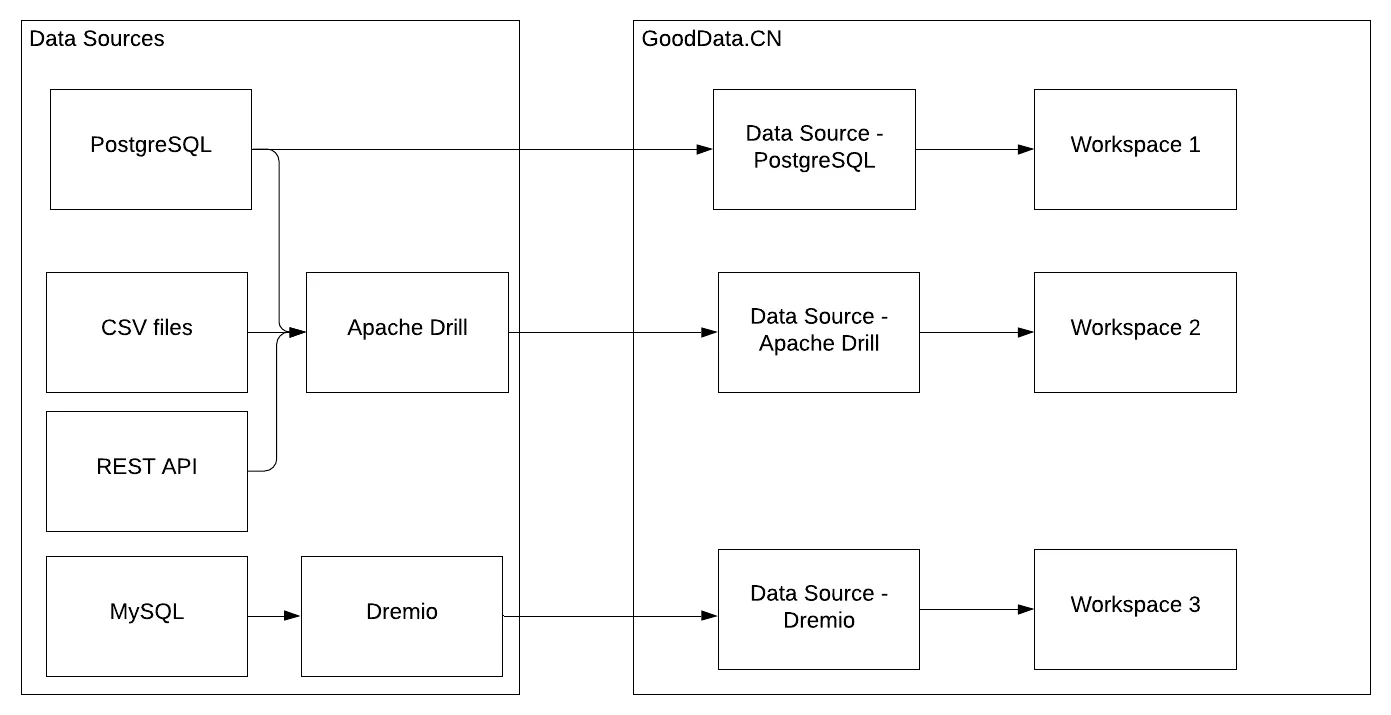
The diagram illustrates how you can use Data Sources and Data Source Managers in GoodData:
Data Source with native support
A user in Workspace 1 can build visualizations only on top of PostgreSQL, which is connected directly as a native data source.Data Source federation
A user in Workspace 2 can federate data from all Data Sources available in the Apache Drill DSM (CSV files, REST API, and the same PostgreSQL as in Workspace 1).Data Source without native support
A user in Workspace 3 can query the MySQL database through the Dremio DSM.
Benefits coming from Data Source Managers
There are multiple benefits to DSMs that may prove useful to the management and visualization of your data through the GoodData platform:
Federation of Data Sources
You can integrate many Data Sources and create a logical data model (LDM) on top of them. Then you can query datasets coming from multiple Data Sources, and the DSM can handle such queries.Integration of additional Data Sources
You can use DSMs to manage Data Sources that GoodData cannot connect with JDBC drivers, for example:- Files and object storage services like AWS S3
- MongoDB
- Elasticsearch
- Kafka
- REST API
Tip: You can skip using a data source manager and use FlexConnect instead. FlexConnect lets you connect to almost any data source, including streaming data, structured and unstructured datasets, databases, third-party platforms, and machine learning models.
Performance
You can use DSMs to cache results from your Data Sources in a format optimized for analytical use cases. GoodData querying the optimized cache performs significantly better. Additionally, you can deploy DSMs as clusters providing horizontal scalability.Resiliency (SLA)
You can deploy DSMs as clusters to provide sufficient resiliency. There is no single point of failure.Optimization of costs
Offloading queries from underlying Data Sources can save significant costs, primarily when you use Data Sources, which you pay, e.g., per hour.
Preparing Data Source Managers for GoodData
GoodData uses metadata from a Data Source to create a logical model. Some Data Sources (CSV files, APIs, or others) do not provide such metadata. Similarly, DSMs do not provide information about referential integrity.
You may use the following strategies to create a better logical data model in GoodData:
- Create an object (table, view, dataset) on top of the Data Source and CAST the data types of columns accordingly.
- Use LDM Modeler and create the primary keys (grains) and their references manually.
- Utilize the naming conventions if you want GoodData to generate the LDM for you.
You can find more specific guidelines on how to deploy and prepare your DSM in the documentation of each DSM.