Create a Google BigQuery Data Source
Follow these steps to connect to a Google BigQuery data warehouse and create a Google BigQuery data source:
Refer to Additional Information for additional performance tips and information about Google BigQuery feature support.
Configure User Access Rights
To connect your BigQuery data warehouse and GoodData, we recommend that you use a Google Cloud Platform service account. For sufficient level of access, ensure your service account has the following user roles and permissions:
Steps:
Grant your service account the following user roles:
bigquery.dataViewerbigquery.jobUser
For more information see Google Cloud documentation Service Accounts and Access Control.
Ensure your service account has the following permissions:
bigquery.jobs.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.list
Get Google Service Account Key File
GoodData requires the use of a Google service account key file to integrate your BigQuery project with the GoodData workspace and create a data source.
The file is used to import most of the settings when you establish the connection between your BigQuery project and GoodData. The following information is extracted:
- Service account email
- Service account key ID
- Google project ID
To learn how to create service account key files, see Google Cloud documentation Create a service account key.
Create a Google BigQuery Data Source
Once you have configured your Google Cloud Platform service account and downloaded a Google service account key file, you can proceed to create a Google BigQuery data source that you can then connect to.
Steps:
On the home page switch to Data sources.
Click Connect data.
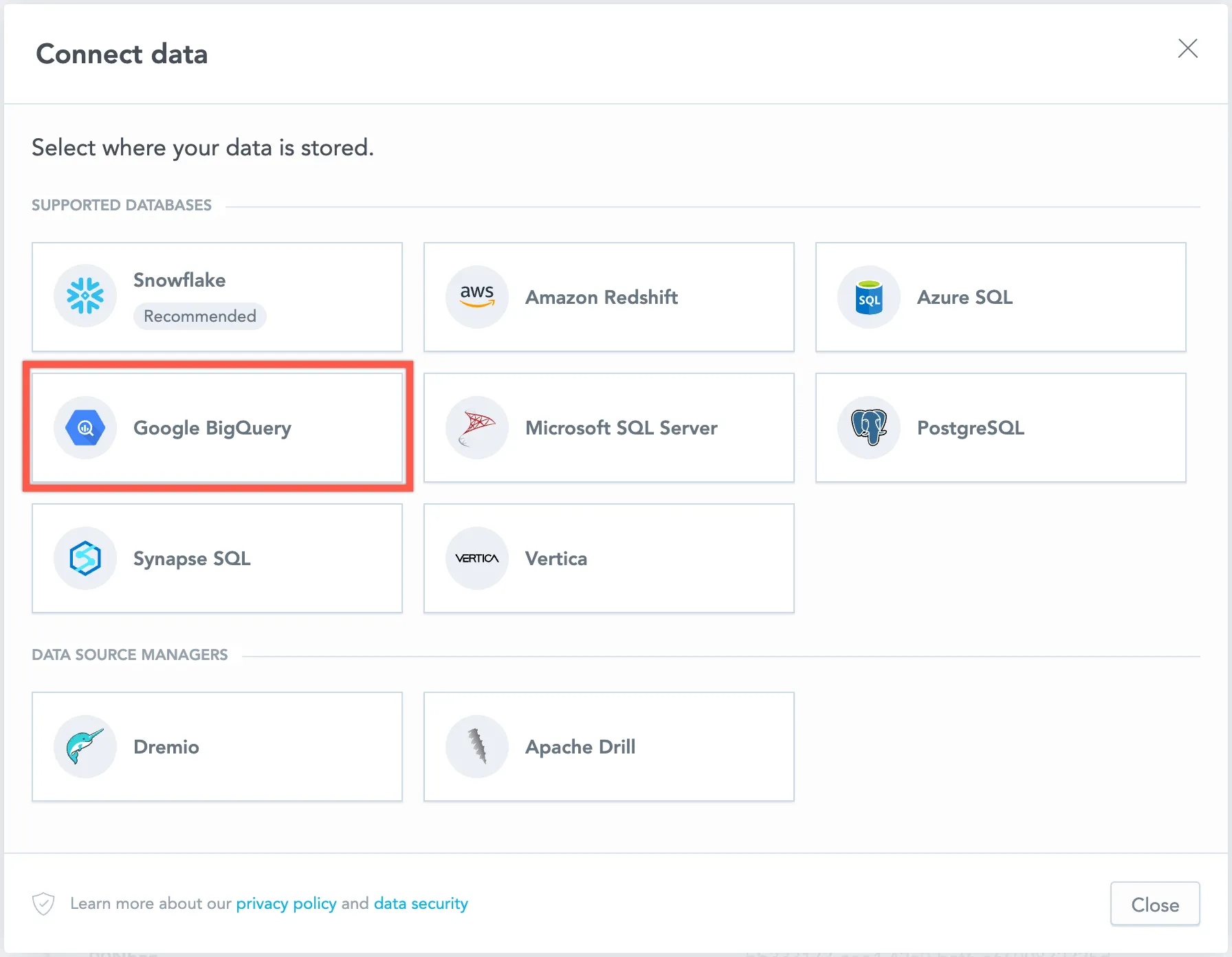
Select Google BigQuery.
The following dialog opens:
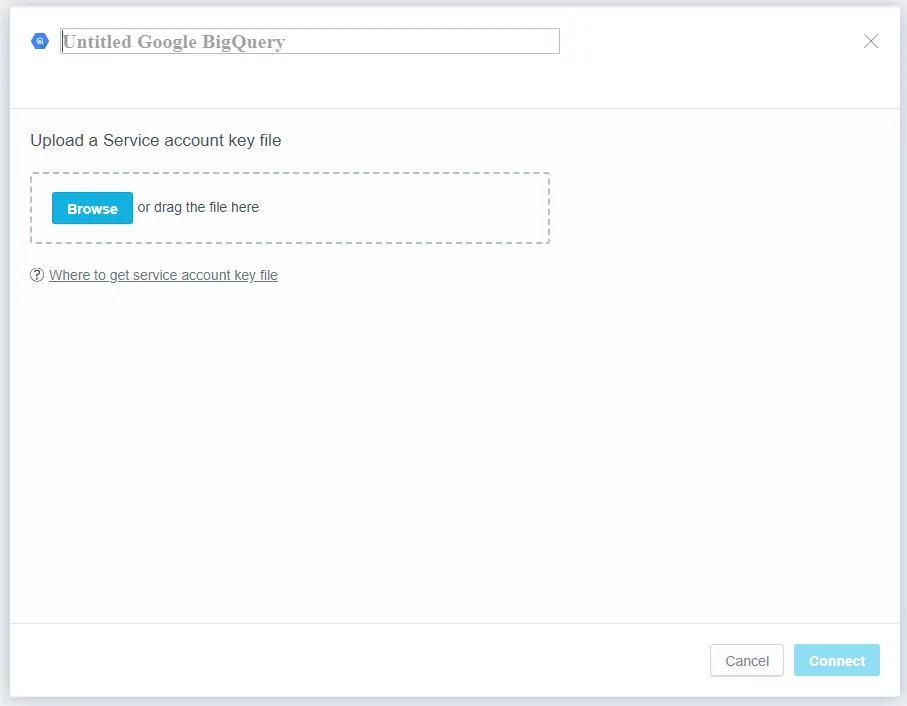
Give the data source a name and upload your Google service account key file.
Click Connect.
The following dialog opens:
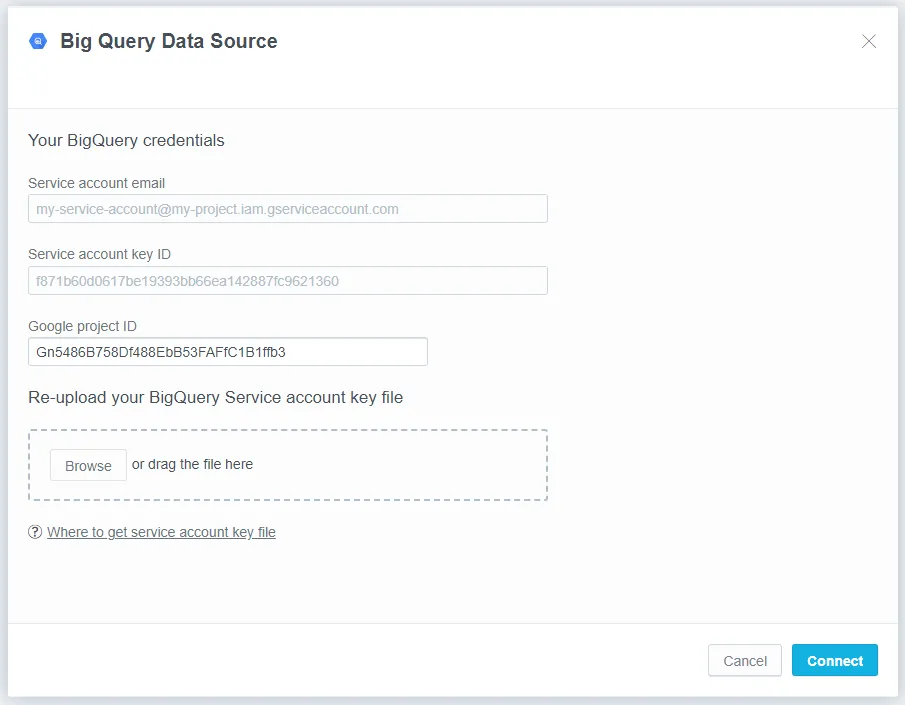
Your Google BigQuery credentials are filled out for you automatically based on the service account key file.
Click Connect.
The following dialog opens:
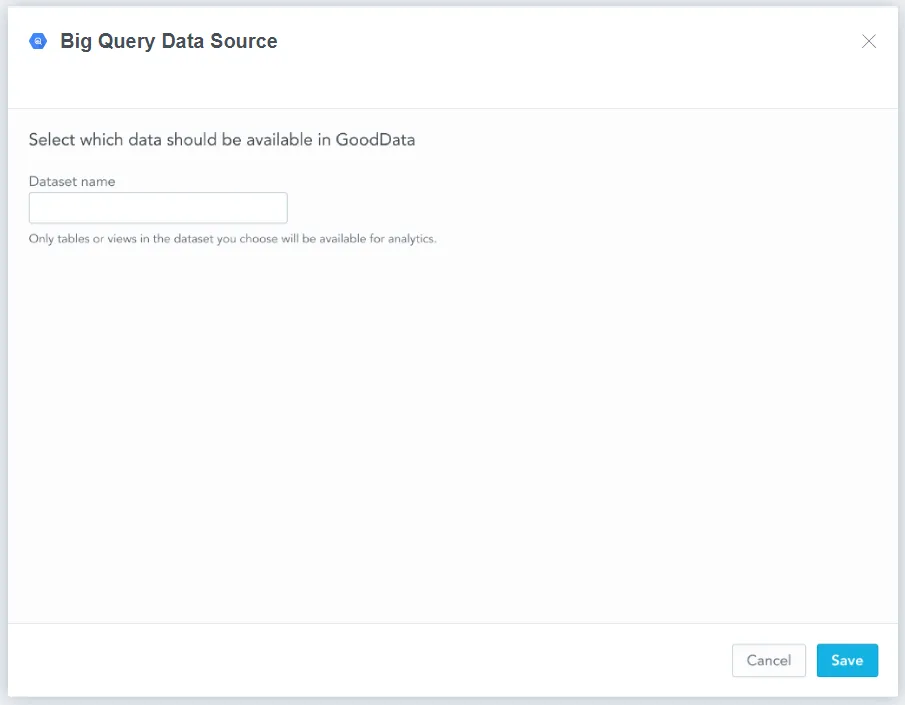
Fill in the name of the Google BigQuery dataset that you want to use in GoodData analytics and click Save.
You have created a Google BigData data source.
Note that only service account authentication is supported. Before you follow the steps below, create a token by encoding your Google service account key file JSON to Base64. In Bash you can encode the JSON to Base64 by running the following command:
base64 service_account.json
Note that the ProjectID specified in the parameter projectId is prioritized over the ProjectID defined in the service account.
Steps:
Create a Google BigQuery data source with the following API call:
curl $HOST_URL/api/v1/entities/dataSources \ -H "Content-Type: application/vnd.gooddata.api+json" \ -H "Accept: application/vnd.gooddata.api+json" \ -H "Authorization: Bearer $API_TOKEN" \ -X POST \ -d '{ "data": { "attributes": { "name": "<data_source_display_name>", "type": "BIGQUERY", "token": "<base64_value_of_google_service_account_key_file>", "schema": "<bigquery_dataset_name>", "parameters": [ { "name": "projectId", "value": "<google_project_id_value>" } ] }, "id": "<unique_id_for_the_data_source>", "type": "dataSource" } }' | jq .To confirm that the data source has been created, ensure the server returns the following response:
{ "data": { "id": "<unique_id_for_the_data_source>", "type": "dataSource", "attributes": { "parameters": [ { "name": "projectId", "value": "<project_id_value>" } ], "decodedParameters": [ { "name": "clientEmail", "value": "<service_account_email>" }, { "name": "keyId", "value": "<service_account_key_id>" }, { "name": "projectId", "value": "<google_project_id_value>" } ], "name": "<data_source_display_name>", "type": "BIGQUERY", "schema": "<bigquery_dataset_name>" } }, "links": { "self": "$HOST_URL/api/v1/entities/dataSources/<unique_id_for_the_data_source>" } }
Create a Google BigQuery data source with the following API call:
from gooddata_sdk import GoodDataSdk, CatalogDataSource, BasicCredentials
host = "<GOODDATA_URI>"
token = "<API_TOKEN>"
sdk = GoodDataSdk.create(host, token)
sdk.catalog_data_source.create_or_update_data_source(
CatalogDataSourceBigQuery(
id=data_source_id,
name=data_source_name,
schema=os.environ["BIGQUERY_SCHEMA"],
credentials=TokenCredentialsFromFile(
file_path=Path(os.environ["BIGQUERY_CREDENTIALS"])
),
parameters=[{"name": "projectId", "value": "abc"}],
)
)
Additional Information
Ensure you understand the following limitations and recommended practice.
Unsupported Features
GoodData does not support the following features:
- The PERCENTILE function.
- The REGR_R2 function.
- Referential integrity:
- BigQuery does not support referential integrity (primary and foreign keys).
- Primary and foreign keys cannot be utilized when generating a logical data model (LDM).
- If you want to generate primary keys and references into the LDM automatically, you can utilize database naming conventions as an alternative solution.
- Query timeout is not supported for Google BigQuery yet.
Supported URL Parameters
Note that for Google BigQuery the data source API /entities/dataSources does not use the url parameter that is used to define a JDBC URL. Parameters are instead defined in the API definition attribute/parameters. Only the following parameter is supported:
- projectId
Note that dataset is not specified in parameters section. The API definition attributes/schema is used instead.
Performance Tips
If your database holds a large amount of data, consider implementing the following practices:
- Denormalize the relational data model of your database.
- This helps avoid large JOIN operations. Because BigQuery is a columnar database, queries read only the required columns and each column is compressed separately.
- Utilize clustered tables.
- Data can be pruned when using clustered columns.
- Utilize partitioned tables.
- To map the BigQuery provided pseudo-columns
_PARTITIONDATEand_PARTITIONTIMEonto the LDM:- Reference your date dataset in the dataset mapped to the partitioned table.
- Map the foreign key representing the reference to your date dataset to one of the pseudo-columns mentioned above.
- To map the BigQuery provided pseudo-columns
- Utilize materialized views.
- Changes to underlying tables are propagated to related materialized views. They are always consistent.
- Materialize the results of JOINs and aggregations. These are executed very often as a result of using dashboards or visualizations.
- Map materialized views and their columns to datasets and the LDM. You can utilize them in metrics, visualizations, and dashboards.